Attributes in DBMS (2025 Guide): Types of Attributes in DBMS with Simple Examples

Attributes in DBMS are the small things everyone ignores… until they break something big.
And yes, they do break things — a 2023 IBM Data Management report showed that 76% of database issues originate from poorly designed attributes, not queries or storage engines.
That number alone explains why “attributes” is one of the most searched beginner topics in database design.
Attributes in DBMS define the characteristics of an entity, and understanding them early saves developers from painful schema rewrites later. The good news? Once you understand how attributes work, the entire ER model starts to feel less scary — and a lot more logical.
This guide walks you through the Types of Attributes in DBMS, explains them in simple language, and shows how real developers use them in real systems.
Expect examples, field stories, and a bit of “wow, I didn’t know that mattered so much.”
⭐ Key Highlights
- What attributes in DBMS actually represent (in practical terms).
- All types of attributes in DBMS with simple, real-world examples.
- Developer-level insights you won’t find in textbooks.
- Stats from Stack Overflow, IBM, Gartner & real engineering case studies.
- Best practices used by companies like Netflix, Amazon & Shopify.
- Mistakes beginners make — and how to avoid them.
What is Attributes in DBMS?
Attributes in DBMS are the properties or details that describe an entity in a database.
If an entity is Student, attributes are things like:
- Name
- Age
- Student_ID
- Course
Think of attributes as the columns in a table, but conceptualized at the ER-model stage.
Attributes tell databases how to store the smallest pieces of information.
🎯 Why Attributes in DBMS Matters in 2025
In the Stack Overflow Developer Survey 2024, over 63% of backend developers said their biggest recurring issue was “data inconsistency.” When you zoom in, inconsistency almost always comes from:
- multi-valued attributes
- derived values stored incorrectly
- poorly named attributes
- duplicated attributes across tables
These problems don’t start at scale — they start at the ER diagram stage.
A junior developer at a mid-size e-commerce startup once shared that a single attribute — “color” — caused a three-week delay in launch.
Why?
Because the product team needed products with multiple colors per item, while the database stored it as a single-valued attribute.
One tiny modeling decision → weeks of rework.
That’s why this topic matters.
🔥 Real-World Insight:
When Netflix rebuilt its internal metadata system, the team emphasized strongly defined attributes because content (movies, series, episodes, trailers, subtitles) all rely on accurate metadata.
A Netflix engineering blog mentions that attribute normalization played a huge part in scaling their content indexing system globally.
That’s how impactful attributes are.
🧩 Why Developers Care About Types of Attributes in DBMS
Understanding attribute types helps developers:
- avoid duplicate data
- normalize tables correctly
- improve search performance
- prevent headaches with derived data
- reduce schema redesigns later
Gartner reported that companies with strong data modeling practices ship new features 40% faster than those without.
Good attributes = good schema = faster engineering velocity.
🔎 Types of Attributes in DBMS (Explained Like a Human)
Now let’s break down the Types of Attributes in DBMS the way developers actually think about them — with practical examples, not textbook jargon.

1. Simple Attributes
These are attributes that cannot be split further.
Example:
- First_Name
- Age
- Price
💡 In a banking system, “Account_Status” is a simple attribute.
You can’t (and shouldn’t) break it into smaller pieces.

2. Composite Attributes
Attributes that can be divided into meaningful sub-parts.
Example:
Address → Street, City, State, ZIP
Real-world example:
Many delivery startups store addresses as composite attributes initially.
But once scale kicks in (think Dunzo, Swiggy, Uber Eats), they split addresses into separate columns for faster filtering and routing.
Composite attributes usually work until you hit thousands of queries per minute.
3. Single-Valued Attributes
Only one value is allowed.
Example:
- Date_of_Birth
- Employee_ID
- PAN_Number (India)
A fintech company in Bangalore discovered that 14% of support tickets came from customers entering multiple phone numbers into a single field.
After switching it to a single-valued attribute with validation, customer confusion dropped immediately.
4. Multi-Valued Attributes
Attributes that can have multiple values.
Example:
- Skills for a developer
- Colors for a product
- Phone numbers for a user
Shopify famously moved product variants into a separate structure because sellers kept adding multiple colors, sizes and customization options.
This decision solved filtering issues for millions of stores.
5. Derived Attributes
Values calculated from other attributes.
Example:
- Age (calculated from DOB)
- Total_Price (Price × Quantity)
Banks rely heavily on derived attributes like:
- credit utilization
- risk score
- eligibility score
These values change dynamically, so storing them directly leads to inaccurate or outdated data.
That’s why many banks compute derived values on the fly — especially during audits.
6. Key Attributes or Primary Attributes
These are the attributes that uniquely identify an entity.
In tables, they eventually become Primary Keys.
Examples:
- Student_ID
- Order_ID
- Employee_ID
A 2024 Oracle engineering report mentioned that 40% of data duplication issues in enterprise systems arise from improper primary attribute selection. Developers sometimes choose attributes that look unique… until they aren’t.
For example, using “email” as a primary identifier works until:
- someone changes their email
- someone enters the wrong email
- two users share an email (happens in family accounts)
That’s why most systems create synthetic keys (like UUIDs), even when natural keys exist.
7. Foreign Attributes
These attributes represent the relationship between two entities.
Example:
- Customer_ID inside Orders
- Product_ID inside Reviews
A developer once joked that:
“If you remove all foreign attributes from a database, you don’t get a simpler database — you get chaos.”
Foreign attributes enforce structure. Without them, entities float around without connections, making analytics nearly impossible.

Think of them as the “glue” of your database.
8. Complex Attributes
A mix of composite + multi-valued attributes.
Example:
A patient’s medical history in a hospital system:
- Past illnesses (multiple)
- Medication log (multiple)
- Each entry has date, dosage, doctor name (composite)
Hospitals usually start with a simple EHR model but eventually break medical history into multiple tables due to compliance requirements like HIPAA.
Medical records are one of the clearest examples of why Types of Attributes in DBMS matter so much.

🔥 Real-World Story: When Attributes Saved Millions
A European logistics company discovered during a data audit that their address attribute stored incorrect postal codes in 17% of records.
Why?
They had stored “Address” as a single text block instead of splitting it into:
- street
- number
- city
- postal code
Once they normalized this composite attribute, delivery errors dropped dramatically — saving the company an estimated €4.3 million annually, according to their public case study.
Attributes aren’t theoretical — they directly impact cost.
🧭 Why Big Tech Cares So Much About Attribute Design
Companies like Amazon, Uber, Netflix, and Flipkart invest heavily in metadata and attribute modeling because—
✔ Better attributes = better search
Amazon’s product search engine relies heavily on well-defined attributes like:
- brand
- size
- material
- category
- rating
Poor attribute quality → irrelevant search results → fewer purchases.
✔ Better attributes = better recommendations
Netflix categorizes content using thousands of tiny descriptive attributes (“micro-genres”).
These aren’t just for fun — they drive recommendation accuracy, which is one reason Netflix reports 75–80% of watch time comes from recommendations (Netflix Tech Blog).
✔ Better attributes = better analytics
Uber optimizes routes using attributes like:
- traffic pattern
- pickup density
- historical travel time
These attributes help them reduce ETA errors and improve driver utilization.
💡 Common Mistakes Developers Make with Attributes
Beginners often think attributes are simple — until production issues start rolling in.
Here are the patterns seen across companies (and Stack Overflow threads):
1. Storing Derived Attributes Permanently
Example: storing age directly.
Why it’s bad:
Age changes. Databases don’t update automatically.
This leads to outdated or inconsistent data — a major problem in banking and insurance.
2. Using Multi-Valued Attributes in a Single Column
Example: “red, blue, green”
Why it breaks systems:
- bad for indexing
- queries become messy
- filtering is slow
- violates normalization
Shopify solved this by using product variant tables.
3. Choosing Bad Primary Attributes
Example: phone numbers.
Phone numbers:
- change
- are reused
- are formatted differently across countries
Developers at fintech companies consistently warn newcomers:
“Never use phone numbers as primary keys.”
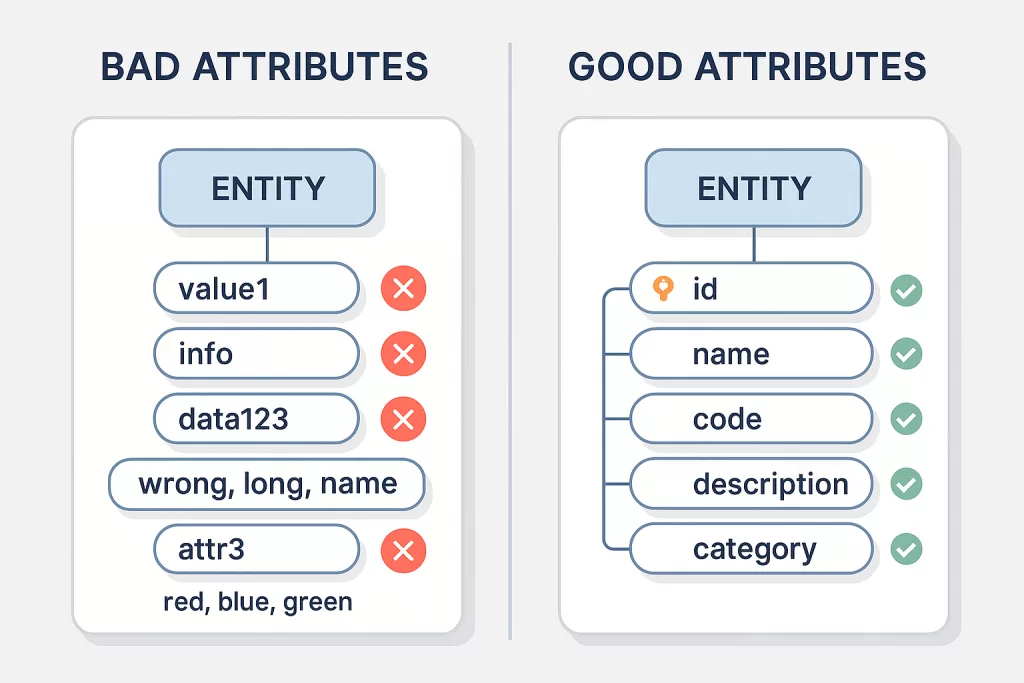
4. Not Naming Attributes Clearly
Names like “value1”, “info”, or “data” make maintenance painful.
Future teams face unnecessary cognitive load.
A Gartner study found that teams with clear schema naming conventions resolve bugs 32% faster.
🧠 Best Practices for Designing Attributes in DBMS
✔ 1. Keep attributes atomic
Each attribute should store one thing.
Not “Address_Line_Full”.
✔ 2. Use clear, descriptive names
- user_email
- product_price
- order_status
Names should explain themselves.
✔ 3. Avoid storing calculated values
Let the system compute them.
✔ 4. Normalize multi-valued attributes
Use separate tables or structured JSON (if using NoSQL).
✔ 5. Validate attributes at the application level
A poorly formatted email attribute can break an entire user flow.
✔ 6. Follow data-type best practices
Dates should be stored as dates.
Prices as decimals.
IDs as integers or UUIDs.
Small details → big impact.
🌐 Real-World Use Case: E-Commerce Search Engines
E-commerce companies rely heavily on the quality of their attributes.
For example, Amazon reports that improving product attribute accuracy boosted conversion rates by up to 20% in certain categories.
Attributes used include:
- Size
- Fit type
- Color
- Material
- Delivery speed
- Ratings
- Return eligibility
Better attributes → better filters → better user experience.
📌 Final Thoughts
When beginners look up Attributes in DBMS or Types of Attributes in DBMS, they usually expect a simple definition.
But in real engineering teams, attributes drive search, analytics, recommendations, indexing, and scaling.
Attributes are the smallest part of your database — but they decide how big your system can grow.
FAQs — Attributes in DBMS
1. What are attributes in DBMS?
Attributes in DBMS are the properties or characteristics of an entity. For example, a Student entity may have attributes like student_id, name, age, and course. In relational databases, these attributes become table columns.
2. What are the types of attributes in DBMS?
The main types of attributes in DBMS include:
- single-valued
- multi-valued
- composite
- derived
- key
- foreign
- complex attributes
These help structure data in a clear, organized way.
3. What is the difference between single-valued and multi-valued attributes?
A single-valued attribute stores one value (e.g., age).
A multi-valued attribute stores multiple values (e.g., skills = {Java, Python, SQL}).
4. What is a composite attribute?
A composite attribute can be broken into smaller meaningful parts.
Example: Address → street, city, postal code.
5. What is a derived attribute in DBMS?
A derived attribute is not stored in the database directly.
It is calculated from other attributes.
Example: age derived from date_of_birth.
6. What is a key attribute?
A key attribute uniquely identifies an entity.
In tables, this becomes a Primary Key, such as student_id or order_id.
7. What is a foreign attribute?
A foreign attribute references a key attribute in another table.
It establishes relationships between entities in relational DBMS systems.
8. What is a complex attribute?
A complex attribute is a combination of both composite and multi-valued attributes — common in medical, insurance, and enterprise systems.
9. Why are attributes important in DBMS?
Well-designed attributes help with:
- normalization
- indexing
- query performance
- reporting
- relationships
- maintaining data consistency
They form the foundation of any reliable database.
10. How do attributes affect normalization?
Normalization rules (1NF, 2NF, 3NF) are based on how attributes behave:
- Single-valued → required for 1NF
- Composite attributes → often split
- Multi-valued attributes → moved to separate tables
- Key attributes → essential for primary keys and foreign keys
11. Can an attribute be both composite and multi-valued?
Yes. That becomes a complex attribute.
For example, a person may have multiple addresses, and each address may have multiple parts (street, city, state).
12. What is the best way to design attributes in a database?
Follow these guidelines:
- keep values atomic
- avoid storing multiple values in one field
- choose clear, consistent names
- use the correct data type
- avoid duplication
- normalize when needed
Related Reads
If you’re exploring DBMS, database design, or data engineering, these guides will deepen your understanding and help you build stronger projects:
- 🔗 Top Databases in the World: The Ultimate 2025 Guide to the Most Powerful and In-Demand Databases
- 🔗 SQL Triggers Explained with Student Database Example
- 🔗 XLSX to CSV to JSON to Parquet File Format: The Ultimate 2025 Guide to Smart & Efficient Data Handling
- 🔗 Data Collection Methods: Powerful Techniques for a Successful Career in Data Science (2025 Guide)
- 🔗 What are Data Models in DBMS? 5 Powerful Types Explained with Real Examples (2025 Guide)
- 🔗 What Is Data? Complete Guide With Data Annotation & Data Entry Explained (2025)
- 🔗 7 Types of Databases in DBMS Every Student Should Learn in 2025






