What is the Data Science Life Cycle? Stages, Frameworks & Workflow Explained

What is the Data Science Life Cycle?
Data Science Life Cycle is a term I heard a hundred times before I actually understood what it felt like to follow it in the real world.
And let me repeat it again—because this is important:
Data Science Life Cycle is the backbone of every good data project. Without it, you’re just coding in circles.
When I worked on my first retail analytics project, I made every mistake possible—wrong assumptions, messy data, incorrect model assumptions… you name it. But understanding the actual flow of the Data Science Life Cycle changed everything.
Suddenly, the chaos made sense.
Suddenly, my work became predictable—even enjoyable.
So if you’re here wondering how data scientists actually move from a simple “business question” to a real, working model… you’re in the right place.
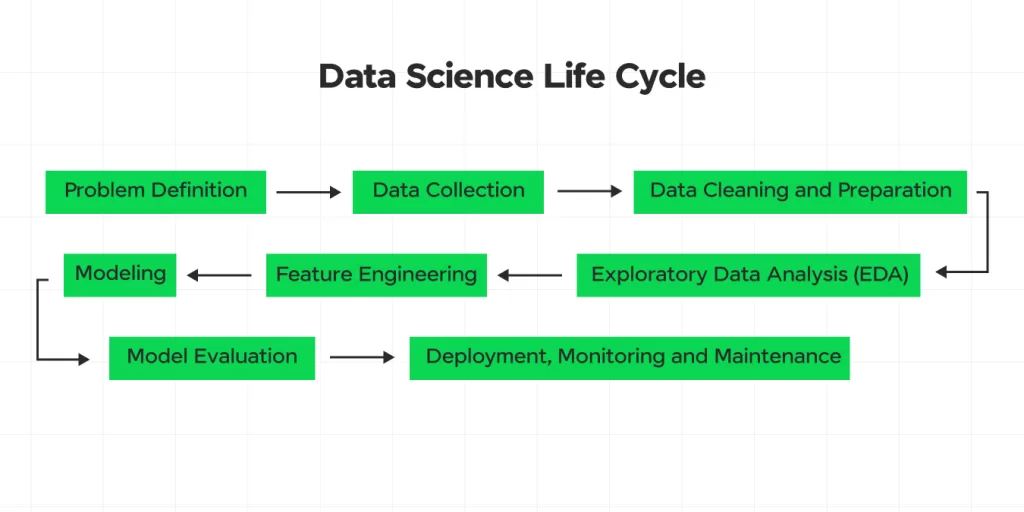
Why the Data Science Life Cycle Matters
If you’ve ever asked yourself:
“How does a data science project actually work from start to finish?”
This article gives you the entire workflow upfront:
👉 It starts with a problem.
👉 Moves into data collection.
👉 Uses data cleaning in data science to fix the messy stuff.
👉 Breaks down your data with EDA.
👉 Builds and evaluates models.
👉 And finally deploys + monitors them.
This is the real end-to-end Data Science Life Cycle—simple, clear, and human.
Problem Statement – The Heartbeat of the Project ❤️
I always say this:
Three-quarters of failures in data science occur due to failure to define the problem well.
During this phase of the Data Science Life Cycle, I would sit and discuss with the stakeholders, put in bothersome questions, and assumptions to test and drill.
One of the e-commerce brands I used to work with said:
“Predict customer churn.”
But, after two conversations, the real issue was:
“Identify customers that will cease buying within 60 days.”
Nothing is the same with that clarity.
Key Things I Do Here:
- Ask “why” at least 3 times
- Translate all the needed situations into quantifiable questions
- Write down assumptions
- Define success metrics
And a clear problem statement is your North Star. ⭐
Data Collection – Where the Treasure Hunt Starts 🗂️
.In this step of the Data Science Life Cycle, I am bringing in the information from:
- SQL databases
- APIs
- Web scraping
- CRMs
- Public datasets like Kaggle
- Social media analytics
A real example:
In the case of a fashion brand prognostic model, I gathered:
- Past sales
- Google Trends data
- Climate patterns
- Influencer mentions
Data Cleaning – The Most Underestimated Stage in Data Science 🧹
Let me be honest with you…
Cleaning data is not enjoyable in data science.
This is where dreams are killed and patience is put to test.
But that is where magic occurs as well.
When doing data cleaning in data science, I work with:
- Missing values
- Duplicates
- Wrong formats
- Inconsistent units
- Weird outliers
- Unforeseen nulls
- Strange values that no human being could create
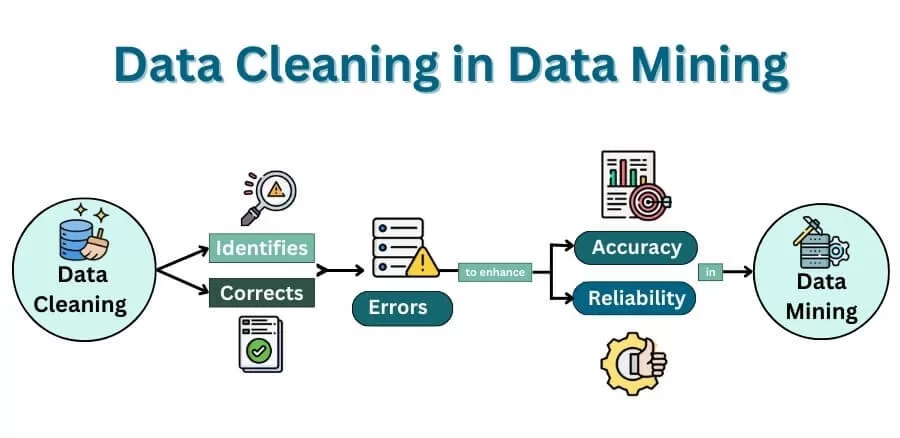
Why this step matters:
Because even the best model fails when fed garbage.
That is why data cleaning in data science is mentioned so many times in the Data Science Life Cycle.
It’s that important.
Currently, I am familiar solely with two methods: Excel and SPSS.
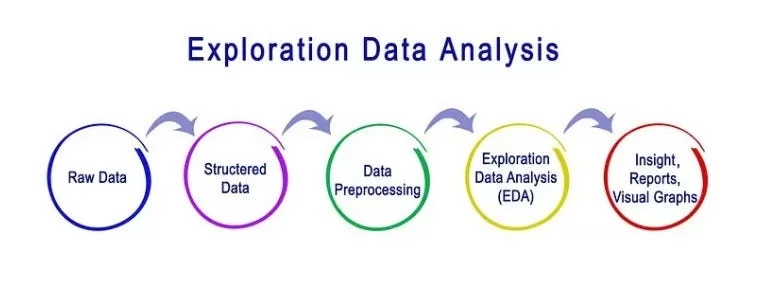
Exploratory Data Analysis (EDA) – The Mystery Box 📊
This is my most preferred part of the Data Science Life Cycle.
EDA is a mystery box — you never know what is inside.
Here, I build:
- Heatmaps
- Trend charts
- Histograms
- Pair plots
- Correlation maps
And questions always hit me:
- Why is this value so high?
- Why did sales drop here?
- How can two variables be correlated unexpectedly?
One time, during EDA of a food chain, I realized that on rainy days, orders were much higher on weekends.
Who do you think applied that knowledge to a specific coupon campaign?
Yep, they made a lot of money from that simple pattern. 💰
Feature Engineering – Carving the Gold 🔧
When data is raw clay, feature engineering is the process of carving it.
At this phase of the Data Science Life Cycle, I:
- Create new features
- Encode categories
- Normalize values
- Use domain knowledge heavily
Real-life example:
To do retail forecasting, I developed features such as:
- “Days since last purchase”
- “Seasonality flags”
- “Holiday spikes”
Each one improved accuracy.
Modeling – Where the Action Really Takes Place 🤖
Here is where I test algorithms such as:
- Random Forest
- XGBoost
- Linear Regression
- Neural Networks
- K-Means
The exciting part of modeling in the Data Science Life Cycle is that all the stuff you cleaned, engineered, and explored finally comes together.
I try dozens of models.
I tweak hyperparameters.
I run cross-validations.
It’s messy… but satisfying.
Model Evaluation – The Reality Check 📉📈
A fantastic model is not just a good one — it’s a good one consistently.
I use metrics like:
- Accuracy
- RMSE
- Precision/Recall
- F1 score
- AUC
This is the stage that requires true honesty.
If the model sucks, admit it. Fix it. Improve it.
Deployment – Releasing the Model Out to the Real World 🚀
This is the least-known phase of the Data Science Life Cycle.
Deployment does not mean simply uploading the model somewhere.
It includes:
- Turning the model into an API
- Integrating with apps
- Establishing monitoring dashboards
- Ensuring timely forecasts
Tools I often use:
- FastAPI
- Flask
- Docker
- AWS Lambda
Want to see your model in action used by thousands of live users?
Pure joy.
Monitoring & Maintenance – Keeping It Alive 🩺
Models decay.
Data changes.
Human behavior shifts.
So I monitor:
- Accuracy drops
- Data drift
- Latency
- Errors
- Feedback loops
A model is a living thing — you cannot deploy it and forget it.
Popular Frameworks in the Data Science Life Cycle
🔹 CRISP-DM
(explained on: https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining)
The most used global standard.
🔹 TDSP
Microsoft’s team-based approach.
🔹 SEMMA
Sample → Explore → Modify → Model → Assess.
🔹 KDD
Focuses heavily on knowledge extraction.
Who Works in the Data Science Life Cycle?
- Data Scientists
- Data Engineers
- Analysts
- Machine Learning Engineers
- Domain Experts
- Project Managers
Everyone is connected. Everyone matters.

Final Thoughts ❤️
The Data Science Life Cycle isn’t just a process.
It’s a journey.
It’s messy, surprising, creative, and deeply rewarding.
From defining the problem to deployment to monitoring, every stage teaches you something new.
And if you’re starting your career now—trust me—you’re stepping into one of the most exciting fields out there.