What is Kruskal Algorithm? Ultimate 2025 Guide with Examples, Pseudocode & Real-World Uses
If you’ve ever wondered how telecom companies connect thousands of network towers with minimum cable cost, how Google Maps optimizes routes, or how AI clusters data efficiently, the answer often traces back to Kruskal Algorithm.
This isn’t just another graph theory topic you cram the night before an exam. It’s a core algorithm behind real-world network optimization and system design—and recruiters expect you to know it cold.
Here’s the crazy part:
✅ Companies lose millions of dollars every year due to poorly optimized networks.
✅ Minimum Spanning Tree (MST) algorithms, including Kruskal’s, help reduce those costs by up to 60%.
✅ The network optimization market is projected to hit $16.2B by 2027.
And guess what?
Whether you’re preparing for DSA interviews, coding competitions, or system design roles, Kruskal’s Algorithm keeps showing up. It’s a classic Greedy Algorithm, a favorite in GATE, UPSC-CS optional CS, university exams, FAANG interviews, and real projects.
So let’s ditch the boring textbook definitions and actually understand Kruskal’s Algorithm the way developers and hiring managers expect.

Key Highlights 🎯
Here’s what you’ll see:
🌟 Clear definition of Kruskal Algorithm (exam + interview ready)
🧠 How it works (with intuition, not just theory)
🪜 Step-by-step process (easy to memorize)
💻 Pseudocode + Implementation (C/Java/Python style)
🔍 Detailed example with visual explanation
⚡ Why it’s a Greedy Algorithm
🌐 Real-world applications in networks, AI, clustering, and more
⏱️ Time & space complexity breakdown
⚔️ Prim’s vs Kruskal Algorithm (comparison table)
🛠️ Best practices + common mistakes developers make
🚀 Career and interview insights (how this can land you a job)
❓ FAQs you’ll probably be asked in exams/interviews
What is Kruskal Algorithm?
Kruskal Algorithm is a Greedy technique used to find the Minimum Spanning Tree (MST) of a connected, undirected, and weighted graph by selecting the edges with the smallest weights while avoiding cycles.
In simple terms:
👉 You have cities (nodes) and roads (edges with cost).
👉 You want to connect all cities using the cheapest possible set of roads.
👉 But you can’t create loops (no wasted paths).
👉 Kruskal Algorithm does exactly that—cheapest, no cycles, full connection.
It works by:
- Sorting all edges by weight (smallest to largest)
- Adding the smallest edge that doesn’t form a cycle
- Repeating until we have V – 1 edges in the MST
And that’s why Kruskal Algorithm is considered one of the simplest yet most powerful algorithms in graph theory.
Kruskal Algorithm Definition
Kruskal Algorithm is a greedy technique used to build a minimum cost spanning tree from a connected, undirected graph by repeatedly selecting the smallest weighted edges that do not form a cycle.
In short: It connects all vertices with the lowest total cost and no cycles, producing an MST (Minimum Spanning Tree).
Why is Kruskal Algorithm Important? (Stats + Career Angle)
Kruskal Algorithm isn’t just an exam topic—it’s a real-world problem solver.
✅ Used in critical industries:
- Network design (5G towers, fiber optic layouts)
- Clustering in Machine Learning
- Electrical grid optimization
- Google Maps & GPS routing
- Supply chain & logistics cost reduction
✅ Why companies love it:
Organizations need to build the cheapest, most efficient networks. MST algorithms like Kruskal cut millions in infrastructure cost.
✅ Industry insight:
Telecom and cloud companies (AT&T, Cisco, AWS) rely on MST algorithms for network topology planning. Logistics giants (Amazon, FedEx) use it to minimize delivery routes.
✅ Career & salary impact:
Graph algorithms are a core skill in FAANG-level system design & DSA interviews.
Average salary for engineers strong in graph algorithms: $120K – $200K+ (FAANG).
✅ Why interviewers love MST problems:
- Tests logical thinking
- Checks greedy algorithm understanding
- Evaluates data structure mastery (Union-Find / Disjoint Set)
- Easy to scale from simple to complex problems
Bottom line: If you understand Kruskal deeply, you’re already ahead of thousands of candidates in competitive exams and tech interviews.
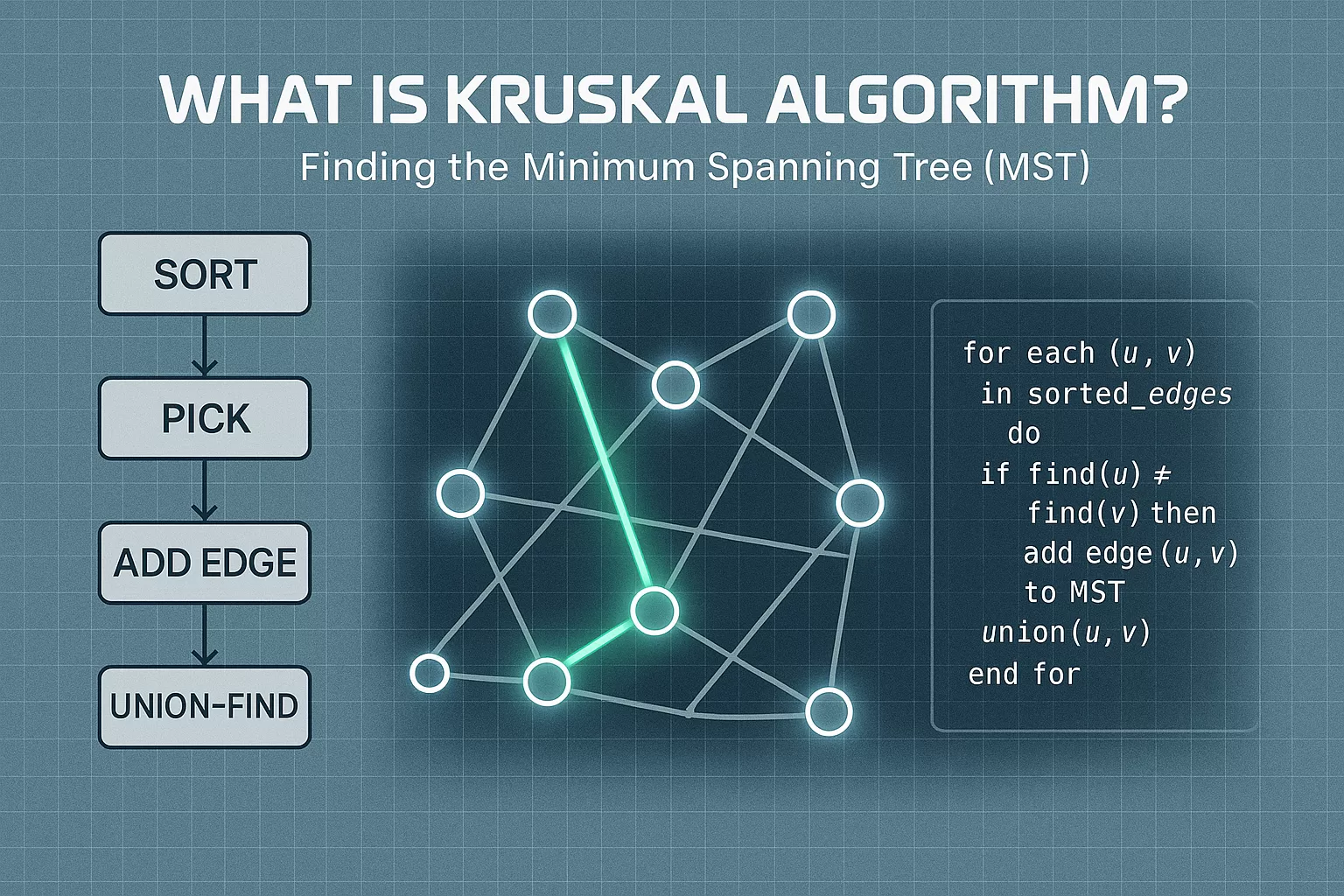
How Kruskal Algorithm Works
Think of Kruskal Algorithm like building the cheapest network from scratch.
Core intuition:
Instead of starting from a single node (like Prim’s), Kruskal looks at all edges globally and picks the cheapest possible edge first, as long as it doesn’t create a cycle.
Here’s the big picture:
- You’re allowed to connect any two nodes.
- But you must avoid loops.
- You always choose the smallest available edge.
- You stop once all nodes are connected.
The secret weapon? → Disjoint Set / Union-Find Data Structure
This structure helps quickly check if two nodes are already in the same connected component.
If yes → skip (it would form a cycle).
If no → connect them (safe to include in MST).
How it differs from Prim’s Algorithm:
| Kruskal | Prim |
|---|---|
| Edge-based | Node-based |
| Sort all edges | Start at a node |
| Good for sparse graphs | Good for dense graphs |
| Needs Union-Find | Needs Priority Queue |
So Kruskal = Sort edges + pick safe ones using DSU.
Kruskal Algorithm Steps ✅
Follow this formula and you’ll never forget it:
👉 Step 1: Sort all edges in non-decreasing order of weight
👉 Step 2: Pick the smallest edge
👉 Step 3: Check if it forms a cycle using DSU (Disjoint Set Union)
👉 Step 4:
- ✅ If NO cycle → Include it in MST
- ❌ If cycle → Skip it
👉 Step 5: Repeat until MST has (V – 1) edges
✨ Bonus Tip:
Use emojis or visuals when revising:
🔽 Sort → 🔗 Connect smallest edge → 🔍 Check cycle → ✅ Add or ❌ Skip → 🔁 Repeat → 🎉 Done (V–1 edges)
This is the heart of Kruskal Algorithm, and everything else builds on top of it.

Kruskal Algorithm Pseudocode
KRUSKAL(G):
MST = {} // Resulting Minimum Spanning Tree
sort edges of G by weight // Step 1: Sort all edges
create a disjoint set DSU // For cycle detection
for each edge (u, v, w) in sorted edges:
if FIND(u) != FIND(v): // Step 2: Check if u and v belong to different sets
MST.add(edge) // Step 3: Safe to add (no cycle)
UNION(u, v) // Step 4: Merge sets
endif
endfor
return MST
Logic Explanation:
- Sort → ensures we always pick the smallest edge.
- DSU (Disjoint Set Union) → efficiently detects cycles.
- Only V-1 edges are added.
- Greedy choice at each step → ensures minimum cost spanning tree.
Kruskal Algorithm Example
Graph (ASCII visualization)
(2)
A ----- B
| \ |
4 \3 |1
| \ |
C ----- D
(5)
Step 1: List all edges with weights
- A-B (2)
- B-D (1)
- A-C (4)
- A-D (3)
- C-D (5)
Step 2: Sort edges by weight ✅
- B-D (1)
- A-B (2)
- A-D (3)
- A-C (4)
- C-D (5)
Step 3: Build the MST step-by-step
| Step | Edge | Added? | Reason |
|---|---|---|---|
| 1 | B-D (1) | ✅ Yes | First edge |
| 2 | A-B (2) | ✅ Yes | No cycle |
| 3 | A-D (3) | ❌ No | Forms cycle (A-B-D-A) |
| 4 | A-C (4) | ✅ Yes | No cycle |
| 5 | C-D (5) | ❌ No | Already connected |
✅ Final MST:
Edges: B-D (1), A-B (2), A-C (4)
Total Cost = 1 + 2 + 4 = 7

Kruskal Algorithm in Python /C / Java /
✅ Python Example
# Kruskal Algorithm in Python
class DSU:
def __init__(self, n):
self.parent = list(range(n))
def find(self, x):
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x])
return self.parent[x]
def union(self, x, y):
self.parent[self.find(x)] = self.find(y)
# Graph edges: (weight, u, v)
edges = [(1, 1, 3), (2, 0, 1), (3, 0, 3), (4, 0, 2), (5, 2, 3)]
edges.sort()
dsu = DSU(4)
mst = []
cost = 0
for w, u, v in edges:
if dsu.find(u) != dsu.find(v):
dsu.union(u, v)
mst.append((u, v, w))
cost += w
print("MST:", mst)
print("Total Cost:", cost)
✅ Output:
MST: [(1, 3, 1), (0, 1, 2), (0, 2, 4)]
Total Cost: 7
✅ Line-by-line Highlights:
- Sort edges by weight.
- Use DSU to avoid cycles.
- Add smallest valid edges until MST complete.
Kruskal Algorithm in Data Structures / DAA
In Data Structures & Algorithms (DSA) and Design and Analysis of Algorithms (DAA) courses, Kruskal Algorithm is a core topic.
Academic Perspective:
- Type: Greedy Algorithm
- Problem: Minimum Spanning Tree (MST)
- Graph Type: Weighted, Connected, Undirected
- Uses: Shows disjoint sets, sorting, and cycle detection.
Graph Representation:
- Edge List (best for Kruskal).
- Adjacency List/Matrix (converted to edge list).
Why Interviewers Ask It:
✅ Tests understanding of greedy strategy
✅ Tests DSU / Union-Find knowledge
✅ Appears in FAANG coding rounds
✅ Basis for many advanced algorithms (e.g., clustering, network design)
Real-world Use Cases of Kruskal Algorithm
🌐 1. Networking (Fiber / Cable Connections)
Connect cities with minimum wiring cost without cycles.
👥 2. Social Network Clustering
Group similar users by connection closeness.
🧠 3. Machine Learning (Clustering)
Used in Hierarchical Clustering (Agglomerative) to merge closest clusters.
🤖 4. AI Pathfinding
Finds minimal connection paths in open-world games or simulations.
🖼️ 5. Image Segmentation
Merge pixels/regions based on similarity → reduces noise.
🚚 6. Logistics & Supply Chain
Design minimum cost delivery routes or pipeline layouts.

✅ Why Kruskal Algorithm is preferred?
| Feature | Why it wins |
|---|---|
| Works well with sparse graphs | Few edges → fast & efficient |
| Simple implementation | Just sort + union-find |
| Greedy & optimal | Always gives minimum cost |
| Scales well | Used in industry systems |
Time Complexity of Kruskal Algorithm
🔹 Sorting Edges: O(E log E)
We sort all edges by weight. This is the most expensive step.
🔹 Union-Find Operations: O(log V) (per operation)
Using path compression + union by rank, each union/find is almost constant-time (amortized).
✅ Final Time Complexity:
O(ElogE)\boxed{O(E \log E)}O(ElogE)
Since in a connected graph, E ≥ V, we can also write it as: O(ElogV)O(E \log V)O(ElogV)
🧠 Memory Usage:
- Storing edges → O(E)
- DSU parent & rank arrays → O(V)
- MST result → O(V)
✅ Total Space Complexity: O(E + V)
⚔️ Practical Performance: Kruskal Algorithm vs Prim
| Scenario | Faster Algorithm |
|---|---|
| Sparse graph (few edges) | ✅ Kruskal |
| Dense graph (many edges) | ✅ Prim (with priority queue) |
| Edge list input | ✅ Kruskal |
| Adjacency list / matrix input | ✅ Prim |
Takeaway:
👉 Kruskal is best for edge-based problems.
👉 Prim is best for node-based expansions.
Prim’s vs Kruskal Algorithm
📊 Comparison Table
| Feature | Kruskal’s Algorithm | Prim’s Algorithm |
|---|---|---|
| Approach | Greedy on edges | Greedy from nodes |
| Data Structure | Sorting + DSU | Priority Queue / Min-Heap |
| Best For | Sparse graphs | Dense graphs |
| Graph Type | Works only on connected | Works on connected |
| Input Format | Edge list | Adjacency list/matrix |
| Time Complexity | O(E log E) | O(E + V log V) (with heap) |
| Implementation Difficulty | Medium | Slightly easier |
| Uses Cycle Check? | ✅ Yes | ❌ No |
| Builds | Forests -> MST | Grows one tree |
✅ When should a developer pick which?
✅ Use Kruskal Algorithm when:
- Edge list is given
- Graph is sparse
- You need to avoid cycles manually
- Great for clustering problems
✅ Use Prim when:
- Adjacency list is available
- Graph is dense
- You start from a specific node
- Faster with heap + adjacency list
Final Insight:
⮕ Kruskal Algorithm = “Sort edges, avoid cycles”
⮕ Prim = “Grow tree from a root”
Best Practices (Developer Insights + Why)
✅ Use Edge List + DSU
→ Efficient and clean. Avoid adjacency matrices for Kruskal Algorithm.
✅ Optimize Sorting
→ Use built-in sorting (Timsort in Python, quicksort/mergesort in C++/Java).
✅ Avoid Naive Cycle Detection
❌ DFS/BFS to detect cycles = slow
✅ Use Union-Find = super fast
✅ Pre-calculate edges
→ Extract all edges once, not repeatedly from adjacency matrix.
✅ Apply Path Compression & Union by Rank
→ Turns DSU into nearly O(1) operations. Massive performance boost.
Common Mistakes & How to Avoid Them
❌ Mistake 1: Forgetting V – 1 edges rule
✅ Fix: Stop once MST has V – 1 edges. Don’t keep checking extra edges.
❌ Mistake 2: Using Adjacency Matrix
✅ Fix: Use Edge List instead. Adjacency matrix = too many unused edges, slow.
❌ Mistake 3: Not resetting DSU between test cases
✅ Fix: Always reinitialize DSU when running multiple graphs (e.g., coding contests).
❌ Mistake 4: Handling disconnected graphs incorrectly
✅ Problem: Kruskal will return a forest, not a full MST.
✅ Solution: Check if MST has exactly V – 1 edges. If not → graph is disconnected.
Best Practices (Developer Insights + Why)
These are the habits that separate beginners from real-world developers 👇
✅ Use Edge List + DSU (Disjoint Set Union)
- Kruskal works naturally with edge lists, not adjacency matrices.
- DSU makes cycle detection fast and elegant.
Why?
Edge list = fewer operations ✔
DSU = near O(1) union/find ✔
✅ Optimize Sorting
- Use built-in sorting (Timsort, merge sort, quicksort hybrids).
- Don’t write custom sorting unless needed.
Why?
Sorting dominates time complexity. Optimizing this step improves performance the most.
✅ Avoid Naive Cycle Check (DFS/BFS ❌)
- Never use DFS/BFS to detect cycles in each step.
Why?
Cycle check with DFS = O(V + E) per edge → too slow
DSU = almost constant time.
✅ Pre-calculate Edges
Don’t extract edges repeatedly from adjacency matrix or graph.
Why?
Repeated edge generation slows down competitive programming and real systems.
✅ Use Path Compression & Union by Rank
These two tiny optimizations = massive speed boost
- Path Compression → flattens tree
- Union by Rank → keeps tree shallow
Result: Union-Find becomes amortized O(1) 🧠
Common Mistakes & How to Avoid Them
Even smart developers get trapped here. Avoid these! 🚨
❌ Mistake 1: Forgetting V – 1 Edges Rule
Kruskal’s stops when MST has exactly (V – 1) edges.
✅ Fix: Always track count of edges added.
❌ Mistake 2: Using Adjacency Matrix (Bad Choice)
Adjacency matrix = V × V = too big and slow.
✅ Fix: Use Edge List instead.
❌ Mistake 3: Not Resetting DSU
In coding contests or multiple test cases, devs forget to reset.
✅ Fix: Reinitialize DSU for every run.
❌ Mistake 4: Handling Disconnected Graphs Incorrectly
Kruskal will build forest, not full tree.
✅ Fix: After completion, check:
if edges_used != V-1 → Graph is disconnected.
Advanced Variations & Enhancements
Kruskal is not a rigid academic concept—it’s evolving 🚀
🔹 Kruskal with Priority Queue
Instead of sorting full list, use a min-heap to pull smallest edges dynamically.
✅ Saves memory in streaming data.
🔹 Parallel (Distributed) Kruskal Algorithm
Divide edges -> process in parallel -> merge MSTs.
✅ Used in large-scale graph processing (e.g., Apache Spark, Hadoop).
🔹 Kruskal Algorithm in Clustering (Machine Learning)
Minimum spanning tree → break largest edges → form clusters.
✅ Used in hierarchical clustering, image segmentation, anomaly detection.
🔹 Approximation for Massive Graphs
For billions of edges:
- Use sampling
- Use filtering
- Use external memory algorithms
✅ Used in web graphs, social media networks, bioinformatics.
Interview Tips & Frequently Asked Questions
Interviewers LOVE MST! Here’s what they ask 👇
Q1. Define Kruskal’s Algorithm.
A greedy algorithm that finds a minimum cost spanning tree in a connected, undirected graph by sorting edges and adding the smallest non-cyclic edges.
Q2. Why is Kruskal considered “Greedy”?
Because it makes the locally optimal choice (smallest edge) at every step to reach a global optimum.
Q3. When does Kruskal fail?
It cannot handle disconnected graphs to produce a single MST—only a Minimum Spanning Forest.
Q4. Can Kruskal handle negative weights?
✅ YES!
Because MST cares only about cycle-free + minimum weight, not distance or path length.
Q5. Difference between MST and Shortest Path?
| MST | Shortest Path |
|---|---|
| Connects all nodes | Connects start → end |
| No cycles | Cycles allowed |
| Minimizes total weight | Minimizes individual path |
| Uses Kruskal/Prim | Uses Dijkstra/Bellman-Ford |
Q6. Is Kruskal deterministic?
✅ Yes.
If edge sorting is stable and tie-breaking is consistent, output is always the same.
Kruskal Algorithm is one of the most powerful and practical greedy algorithms in computer science. From network design to ML clustering, its impact spans multiple industries—and developers who master it are highly valued.
Whether you’re preparing for coding interviews, competitive programming, or real-world system design, Kruskal gives you the perfect mix of theory + implementation + optimization mindset.
🔗 Related Reads
🔐 RSA Algorithm Explained: How It Protects Your Data & Shapes Tech Careers in 2025
🖥️ 7 Scheduling Algorithms in Operating Systems You Must Know
📘 Algorithms Explained: Essential Reasons to Learn in 2025 and Main Algorithm Types
🚀 QuickSort Algorithm Explained: Why Every Developer Should Master It in 2025
📊 What Is Sorting? A Complete Guide to Sorting Techniques & the Best Sorting Algorithm
✅ What is Selection Sort Algorithm (2025 Guide): Examples & Best Practices
🧠 Greedy Algorithm: Guide, Examples & vs Dynamic Programming
📌 Insertion Sort Algorithm in 2025 – Must-Know Facts, Examples in C, Java, Python & More






