Inference in AI (Artificial Intelligence): A Deep, Simple & Practical Guide (2026)

Artificial Intelligence has moved far beyond research labs and into everyday life. From the moment you unlock your phone with face recognition to the recommendations you see on streaming platforms, AI is constantly working in the background. But the part of AI that actually interacts with the real world is not training—it’s inference.
Many beginners focus heavily on how models are trained, but understanding inference is what truly helps you build real-world AI systems. In this guide, we’ll explore inference in depth—what it is, how it works, why it matters, and how modern systems optimize it for performance at scale.
What is Inference in AI?
Inference in AI is the process of using a trained model to make predictions or decisions based on new, unseen data. Once a model has learned patterns during training, inference is the stage where that knowledge is applied.
Think of it like this: imagine a student preparing for an exam. The studying phase is equivalent to training. The actual exam, where the student answers questions using what they’ve learned, is inference. The quality of answers depends not only on what was learned, but also on how quickly and accurately it can be applied.
In AI systems, inference is what users actually experience. When you speak to a voice assistant, upload an image, or type a query into a chatbot, the system is performing inference in real time to generate a response.
A Simple Example to Understand Inference
Consider a machine learning model built to classify emails as spam or not spam. During training, the model analyzes thousands of labeled emails and learns patterns such as suspicious keywords, unusual formatting, or sender behavior.
Once deployed, the model no longer “learns” in the traditional sense. Instead, when a new email arrives, the model evaluates it based on its learned patterns and outputs a prediction. This moment—when the model processes new input and produces a result—is inference.
This same concept applies across domains. In image recognition, inference determines what object appears in a picture. In recommendation systems, inference decides which product or movie you are most likely to engage with. In self-driving systems, inference helps detect obstacles and make split-second driving decisions.
How Inference Works Step by Step
Although it may seem instantaneous, inference involves a structured pipeline. When a user provides input—whether it’s text, an image, or audio—the system first prepares the data so the model can understand it. This preparation phase is known as preprocessing and might involve resizing images, normalizing values, or converting text into numerical representations.
Once the data is prepared, it is passed through the trained model. In the case of deep learning, this means flowing through multiple layers of a neural network, where each layer extracts and refines features. The final layer produces an output, often in the form of probabilities.
For example, an image classifier might output:
- Cat: 0.92
- Dog: 0.07
- Other: 0.01
The system then selects the highest probability as the prediction. This entire pipeline—from input to output—happens in milliseconds in modern systems.
Types of Inference in Modern AI Systems
Inference is not always performed the same way. Depending on the application, it can take different forms.
Batch inference is used when predictions are made on large volumes of data at once. For example, a company might process millions of customer records overnight to generate insights. This approach prioritizes efficiency over immediacy.
Real-time inference, on the other hand, is designed for instant responses. Applications like chatbots, fraud detection systems, and search engines rely on this type of inference. Here, even a delay of a few milliseconds can impact user experience.
Streaming inference is used when data flows continuously, such as in video feeds or sensor data from IoT devices. Instead of processing data in chunks, the system continuously analyzes incoming information and updates predictions in real time.
Training vs Inference: A Deeper Perspective
Training and inference are two sides of the same coin, but they serve very different purposes. Training is computationally intensive and focuses on learning patterns from historical data. It often requires powerful hardware such as GPUs or TPUs and can take hours, days, or even weeks.
Inference, in contrast, must be fast and efficient. It is executed repeatedly, often millions of times per day in production systems. While training happens occasionally, inference happens continuously. This difference is why optimizing inference performance is such a critical aspect of AI engineering.
Another key difference lies in adaptability. During training, the model adjusts its internal parameters. During inference, those parameters remain fixed, and the model simply applies what it has already learned.
Why Inference is the Core of Real-World AI
Without inference, AI would remain theoretical. A trained model sitting in storage has no practical value unless it is used to generate predictions.
Inference is what powers user-facing features. It enables instant search results, personalized recommendations, voice recognition, and intelligent automation. In business contexts, inference drives decision-making systems, predictive analytics, and real-time monitoring tools.
Performance during inference directly impacts user satisfaction. A slow or inefficient system can lead to delays, poor user experience, and even financial loss. This is why companies invest heavily in optimizing inference pipelines.
Real-World Applications of AI Inference
Inference is deeply embedded in technologies we use every day. In healthcare, AI models analyze medical images to assist doctors in diagnosing diseases. In finance, inference helps detect fraudulent transactions by identifying unusual patterns. In e-commerce, recommendation engines use inference to suggest products tailored to individual users.
Autonomous vehicles rely heavily on inference to interpret their surroundings. Cameras and sensors feed data into AI models, which must instantly identify objects, predict movement, and make driving decisions. Even a slight delay in inference could have serious consequences.
In natural language processing, inference powers chatbots and translation systems. When you type a message into a chatbot, the system interprets your input and generates a response almost instantly. This entire interaction is driven by inference.
Inference in Deep Learning Systems
Deep learning has made inference more powerful but also more complex. Neural networks can contain millions or even billions of parameters, which means running inference efficiently becomes a challenge.
When input data passes through a neural network, each layer performs mathematical operations that transform the data into increasingly abstract representations. Early layers might detect simple features like edges in an image, while deeper layers identify complex patterns such as faces or objects.
Because of the size and complexity of these models, deep learning inference often requires optimization techniques to ensure it runs efficiently, especially on devices with limited resources.
Challenges in AI Inference
Despite its importance, inference is not without challenges. One of the biggest issues is latency—the time it takes for a model to produce a prediction. In applications like real-time translation or autonomous driving, even small delays can be problematic.
Another challenge is model size. Large models consume more memory and require more computational power, making them difficult to deploy on mobile or edge devices. Power consumption is also a concern, particularly for battery-powered devices.
Scalability adds another layer of complexity. Systems must handle thousands or even millions of inference requests simultaneously without performance degradation. Achieving this requires careful system design and optimization.
Techniques to Improve Inference Performance
To address these challenges, engineers use a variety of optimization techniques. One common approach is reducing the precision of model parameters, which decreases memory usage and speeds up computation without significantly affecting accuracy.
Another method involves removing unnecessary parts of the model, making it smaller and faster. Specialized hardware, such as GPUs and AI accelerators, is also used to speed up inference.
In recent years, edge computing has become increasingly popular. Instead of sending data to a remote server, inference is performed directly on the device. This reduces latency and improves privacy, as data does not need to leave the device.
Edge vs Cloud Inference
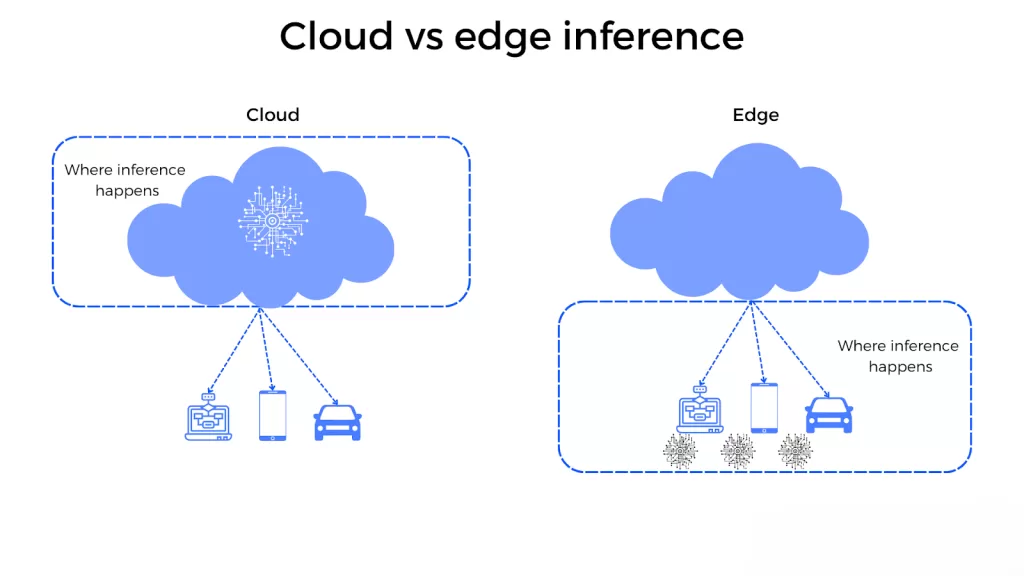
Inference can be performed either on local devices or in the cloud, and each approach has its advantages.
Edge inference happens directly on devices like smartphones, cameras, or IoT sensors. This approach offers faster response times and works even without an internet connection. It is particularly useful for applications where latency is critical.
Cloud inference, on the other hand, leverages powerful servers to handle complex models and large-scale workloads. It is more scalable and can support more sophisticated models, but it depends on network connectivity.
Modern AI systems often combine both approaches, using edge inference for immediate decisions and cloud inference for more complex processing.
The Future of AI Inference
Inference is evolving rapidly as AI continues to grow. Advances in hardware are making it possible to run powerful models on smaller devices. At the same time, new techniques are being developed to make inference faster and more energy-efficient.
Generative AI is also pushing the boundaries of inference. Models that generate text, images, and videos require highly optimized inference pipelines to deliver real-time results. As these technologies become more widespread, the demand for efficient inference will only increase.
Another important trend is the rise of on-device AI, where smartphones and wearable devices perform inference locally. This not only improves performance but also enhances privacy by keeping user data on the device.
Conclusion
Inference is the stage where AI becomes real, practical, and impactful. It transforms trained models into systems that can interact with users, make decisions, and solve problems in real time.
While training builds intelligence, inference delivers it. Understanding how inference works, along with its challenges and optimization techniques, is essential for anyone looking to work with AI in today’s world.
As AI continues to evolve, mastering inference will be just as important—if not more important—than understanding how models are trained. It is the bridge between theory and real-world application, and it is what ultimately defines the success of any AI system.
Want to Learn More About Python & Artificial Intelligence ?, Kaashiv Infotech Offers Full Stack Python Course, Artificial Intelligence Course, Data Science Course & More Visit Their Website course.kaashivinfotech.com.