
Data science has rapidly evolved into one of the most influential disciplines in the modern technological landscape. From personalized recommendations on streaming platforms to fraud detection in banking systems, data science is deeply embedded in everyday digital experiences. However, behind every intelligent system lies a structured approach known as the data science process.
This process is not just about coding or building machine learning models. It is a thoughtful, iterative journey that transforms raw, unstructured data into actionable insights and real-world solutions. In this comprehensive guide, you will explore each stage of the data science lifecycle in depth, with practical understanding and real-world context.
What is the Data Science Process?
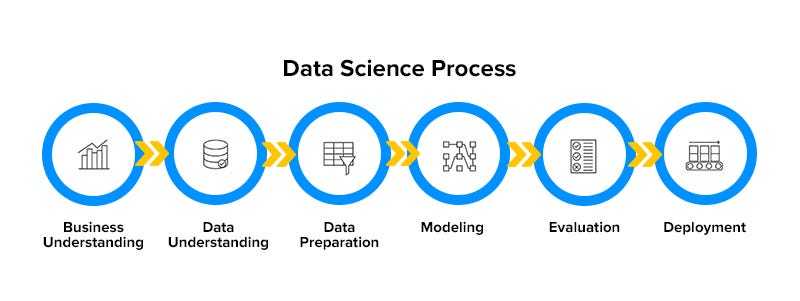
The data science process refers to a systematic framework used to extract knowledge and insights from data. It combines elements of statistics, programming, data engineering, and domain expertise. Unlike a linear workflow, this process is cyclical in nature. Data scientists often revisit earlier steps to refine their work based on new findings or improved understanding.
At its core, the process helps answer one fundamental question:
How can we use data to solve a real-world problem effectively?
Understanding the Lifecycle of Data Science
The data science lifecycle consists of multiple interconnected stages. Each stage plays a critical role in ensuring that the final output is accurate, reliable, and valuable.
Problem Definition: The Foundation of Everything

Every data science project begins with a clear understanding of the problem. Without proper problem definition, even the most advanced models will fail to deliver meaningful results.
This stage involves translating a business requirement into a data-driven question. For instance, a company might want to reduce customer churn. A data scientist must reframe this into a predictive problem, such as identifying which customers are likely to leave in the next month.
A well-defined problem includes clarity on objectives, success metrics, and constraints. It also requires collaboration with stakeholders to ensure alignment between business goals and technical execution.
When this stage is done right, it sets a strong foundation for the entire project.
Data Collection: Gathering the Right Information

Once the problem is clearly defined, the next step is to gather relevant data. Data can come from various sources, including internal databases, APIs, web scraping, sensors, and publicly available datasets.
The quality and relevance of the collected data directly impact the success of the project. Collecting large amounts of irrelevant data can be just as harmful as having too little data.
In real-world scenarios, data is often distributed across multiple systems. A data scientist may need to combine transactional data, user behavior logs, and external datasets to build a complete picture.
It is also important to consider ethical and legal aspects during data collection, such as user privacy and data protection regulations.
Data Cleaning: Preparing Data for Analysis

Raw data is rarely clean or ready for analysis. It often contains missing values, inconsistencies, duplicates, and noise. Data cleaning, also known as data preprocessing, is the process of transforming raw data into a usable format.
This stage can take a significant portion of the project time, sometimes up to 70–80%. Tasks include handling missing values, correcting errors, standardizing formats, and removing irrelevant information.
For example, if a dataset contains missing age values, a data scientist may choose to fill them using statistical methods or remove those records entirely, depending on the situation.
Clean data ensures that subsequent analysis and modeling steps produce accurate and reliable results.
Exploratory Data Analysis (EDA): Discovering Insights
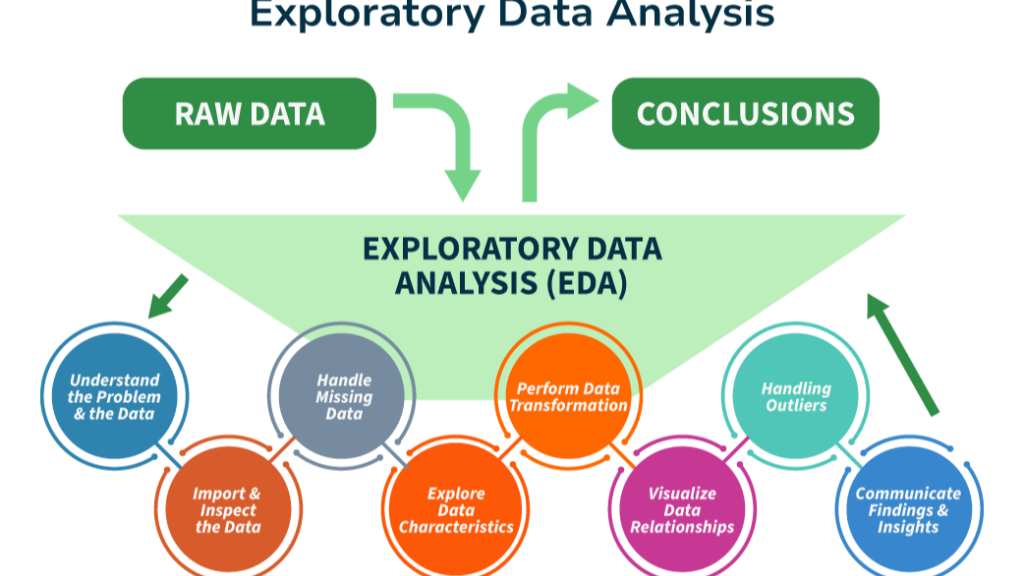
Before building any models, it is essential to understand the data. Exploratory Data Analysis helps uncover patterns, relationships, and anomalies within the dataset.
Through visualization and statistical techniques, data scientists gain insights into how variables interact with each other. For instance, they might discover that customer churn is higher among users with lower engagement levels.
EDA is not just about creating charts; it is about asking meaningful questions and interpreting the results. It often leads to new hypotheses and influences the direction of the project.
This stage bridges the gap between raw data and informed decision-making.
Feature Engineering: Transforming Data into Intelligence
Feature engineering is one of the most critical and creative steps in the data science process. It involves transforming raw data into meaningful features that improve model performance.
For example, instead of using a raw date field, a data scientist might extract the day of the week, month, or whether it is a weekend. Similarly, categorical variables may be converted into numerical formats that machine learning algorithms can understand.
Good feature engineering can significantly enhance the predictive power of a model, while poor feature design can limit its effectiveness.
This stage often requires domain knowledge, as understanding the context of the data helps in creating more relevant features.
Model Building: Turning Data into Predictions
Model building is the stage where machine learning algorithms are applied to the data. The goal is to create a model that can learn patterns from historical data and make predictions on new, unseen data.
Different types of models are used depending on the problem. For example, regression models are used for predicting numerical values, while classification models are used for categorizing data.
The dataset is typically divided into training and testing sets. The model is trained on one portion and evaluated on the other to ensure it generalizes well.
Choosing the right model is important, but it is equally important to avoid overcomplicating the solution. In many cases, simpler models perform just as well as complex ones.
Model Evaluation: Measuring Performance
After building a model, it is crucial to evaluate its performance. This step determines how well the model is likely to perform in real-world scenarios.
Evaluation involves using metrics such as accuracy, precision, recall, and F1-score, depending on the type of problem. The goal is not just to achieve high performance on training data, but to ensure the model performs well on new data.
Overfitting is a common challenge at this stage, where a model performs well on training data but poorly on unseen data. Techniques such as cross-validation help mitigate this issue.
A well-evaluated model provides confidence that the solution is reliable and ready for deployment.
Model Deployment: Bringing Models to Life
A model becomes truly valuable only when it is deployed and used in real-world applications. Deployment involves integrating the model into a production environment where it can generate predictions.
This could be in the form of a web application, an API, or integration into existing business systems. For example, an e-commerce platform may deploy a recommendation model to suggest products to users in real time.
Deployment also requires considerations such as scalability, latency, and system reliability. A highly accurate model is not useful if it cannot handle real-world usage efficiently.

Monitoring and Maintenance: Ensuring Long-Term Success
The data science process does not end with deployment. In fact, deployment marks the beginning of a new phase where the model must be continuously monitored and maintained.
Over time, data patterns may change due to evolving user behavior or external factors. This phenomenon, known as data drift, can reduce model performance.
Regular monitoring helps detect such issues early. Models may need to be retrained with new data or adjusted to maintain accuracy.
This stage ensures that the solution remains relevant and effective over time.
A Real-World Perspective
Consider an online streaming platform aiming to recommend movies to its users. The process begins with defining the goal of improving user engagement. Data is then collected from user interactions, such as watch history and ratings.
After cleaning and analyzing the data, features such as viewing frequency and genre preferences are created. A recommendation model is built and evaluated before being deployed into the platform.
Once deployed, the system continuously learns from new user interactions, improving its recommendations over time. This example highlights how each stage of the data science process contributes to a successful real-world application.
Challenges in the Data Science Process

Despite its structured nature, the data science process comes with several challenges. Data quality issues can hinder analysis, while lack of domain knowledge may lead to incorrect assumptions. Models may become overly complex, leading to overfitting or scalability issues.
Additionally, ethical concerns such as data privacy and bias must be carefully addressed. These challenges require a combination of technical expertise, critical thinking, and responsible decision-making.
The Future of the Data Science Process
As technology continues to evolve, the data science process is becoming more advanced and automated. Tools like AutoML are simplifying model building, while explainable AI is making models more transparent.
Real-time data processing and AI-driven analytics are also transforming how data is used in decision-making. In the coming years, data scientists will need to adapt to these changes and focus more on strategic thinking and problem-solving.
Conclusion
The data science process is a powerful framework that enables organizations to make data-driven decisions and solve complex problems. It is not just about algorithms or tools, but about understanding the problem, working with data effectively, and delivering meaningful results.
By mastering each stage of this process, you can build impactful solutions that create real value. Whether you are a beginner or an aspiring professional, a strong grasp of the data science lifecycle is essential for success in today’s data-driven world.
Want to learn more ??, Kaashiv Infotech Offers Data Analytics Course, Data Science Course, Cyber Security Course & More Visit Their Website www.kaashivinfotech.com.


