
Epochs in Machine learning is often described as teaching computers to learn from data—but how that learning actually happens is where the real depth lies. Among the many concepts involved in training a model, the idea of an epoch stands out as both simple and incredibly powerful. It quietly controls how long your model studies the data, how deeply it understands patterns, and whether it succeeds or fails in real-world applications.
In this comprehensive guide, we’ll go far beyond the textbook definition and explore epochs in a practical, intuitive, and detailed way. By the end, you’ll not only understand what an epoch is, but also how to use it strategically to train better models.
What is an Epoch? A Deeper Understanding

At its core, an epoch represents one complete pass through the entire training dataset. Every data point is fed into the model once, predictions are made, errors are calculated, and the model updates its internal parameters accordingly.
However, understanding epochs purely as “one pass” doesn’t capture their importance. In practice, an epoch is more like a learning cycle. During each cycle, the model slightly adjusts itself, improving its ability to map inputs to outputs. The first epoch often results in rough, inaccurate predictions. By the tenth or twentieth epoch, the model typically begins to stabilize, showing a much stronger grasp of the underlying patterns.
The key insight here is that machine learning models do not learn everything at once. Learning is gradual, and epochs are the rhythm that drives this gradual improvement.
How Training Actually Happens Across Epochs
Training a model involves repeating a loop of operations across data. This loop is executed many times, and epochs define how many full cycles occur.
Inside each epoch, the model processes data in smaller chunks rather than all at once. For every chunk, predictions are generated, compared against actual values, and corrected using optimization techniques such as gradient descent. These corrections accumulate over time, which is why multiple epochs are essential.
What makes this process fascinating is that the model’s behavior evolves across epochs. In the beginning, it makes large corrections because it is far from optimal. As training continues, these corrections become smaller and more refined, eventually leading the model toward convergence—a state where further training produces minimal improvement.
Epochs, Batches, and Iterations: The Hidden Structure
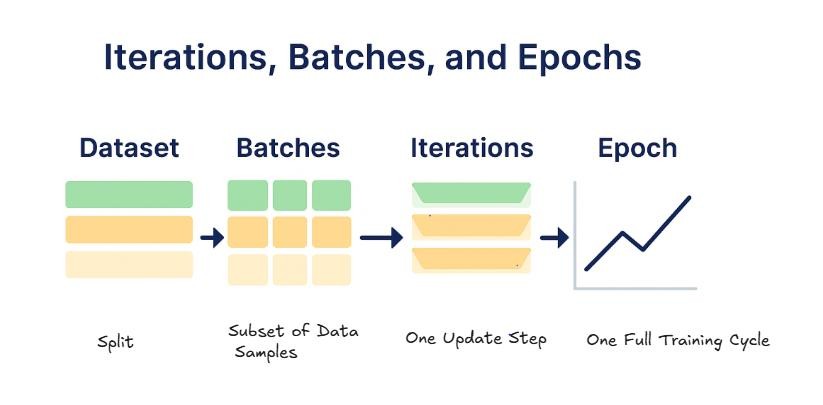
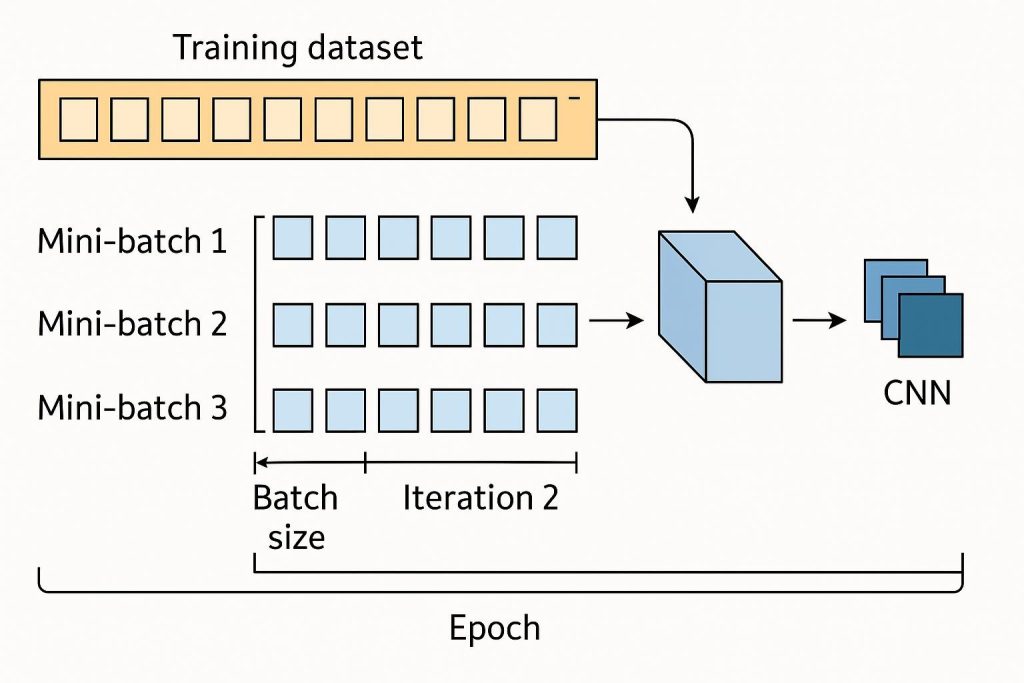
To truly understand epochs, it helps to look at the structure beneath them. Modern machine learning systems rarely process an entire dataset at once. Instead, they divide it into smaller subsets called batches. Each time the model processes one batch and updates its parameters, it completes an iteration.
An epoch, therefore, is made up of multiple iterations—one for each batch needed to cover the entire dataset. This layered structure allows models to train efficiently, especially when working with large datasets that cannot fit into memory all at once.
The interplay between epochs, batches, and iterations also affects training dynamics. Smaller batches introduce more noise into learning but can improve generalization. Larger batches make learning smoother but may require careful tuning of other parameters. Epochs sit above all this, controlling how many times the entire process repeats.
Why Epochs Play a Critical Role in Model Performance
Epochs are directly tied to how well your model performs. They determine whether your model learns too little, just enough, or far too much.
In the early stages of training, each epoch contributes significantly to improving performance. The model begins to detect simple patterns and reduce large errors. As epochs increase, the improvements become more subtle, focusing on refining details and minimizing smaller mistakes.
However, this improvement does not continue indefinitely. After a certain point, the model may start memorizing the training data instead of learning general patterns. This phenomenon, known as overfitting, leads to excellent performance on training data but poor results on unseen data.
This is why epochs must be carefully controlled. They are not just about training longer—they are about training smartly.
The Balance Between Underfitting and Overfitting
Finding the right number of epochs is essentially about striking a balance.
When a model is trained for too few epochs, it fails to capture the complexity of the data. This condition, known as underfitting, results in high error rates and weak predictions. The model simply hasn’t had enough exposure to learn effectively.
On the other hand, training for too many epochs pushes the model into overfitting. At this stage, it becomes overly specialized, learning noise and irrelevant details from the training dataset. While it may appear highly accurate during training, its real-world performance suffers.
The ideal scenario lies somewhere in between. In this balanced state, the model has learned meaningful patterns without becoming overly dependent on the training data. Achieving this balance is one of the most important skills in machine learning.
How to Choose the Right Number of Epochs
Selecting the optimal number of epochs is not about guessing—it’s about observation and adjustment.
A practical approach begins with training the model for a reasonable number of epochs while tracking both training and validation performance. These metrics are often visualized using learning curves. When the validation performance stops improving or begins to decline, it is a strong signal that training should stop.
This is where techniques like early stopping become valuable. Instead of manually deciding when to stop, early stopping monitors performance and halts training automatically at the optimal point. This not only improves model quality but also saves computational resources.
Another important consideration is the size and complexity of the dataset. Larger datasets generally require more epochs because the model needs more time to absorb the available information. Conversely, smaller datasets may require fewer epochs but demand extra caution to avoid overfitting.
Epochs in Deep Learning: A More Intensive Process
In deep learning, epochs take on an even greater significance. Models such as convolutional neural networks and transformers are highly complex, often containing millions or even billions of parameters. Training such models requires many epochs, sometimes running into the hundreds.
During the early epochs, these models learn basic features, such as edges in images or simple word relationships in text. As training progresses, they begin to capture more abstract and complex patterns. The later epochs focus on fine-tuning these patterns to achieve optimal performance.
Because deep learning models are computationally expensive, managing epochs efficiently becomes critical. Training for too long wastes time and resources, while stopping too early leads to suboptimal performance. This is why monitoring and adaptive techniques are widely used in modern workflows.
A Real-World Perspective on Epoch Training
Consider a scenario where you are training an image classification model on a dataset containing tens of thousands of images. Each epoch involves processing every image once, but the real story lies in how the model evolves.
In the first few epochs, accuracy improves rapidly as the model learns basic distinctions. Midway through training, improvements slow down as the model refines its understanding. Toward the end, gains become minimal, and the risk of overfitting increases.
This progression highlights an important truth: epochs are not just repetitions—they represent stages of learning. Understanding these stages allows you to intervene at the right time and achieve better outcomes.
Advanced Strategies for Managing Epochs
As machine learning workflows become more sophisticated, so do the techniques used to manage epochs.
One widely used strategy is early stopping, which prevents overtraining by halting the process when improvements plateau. Another approach involves adjusting the learning rate as training progresses. A higher learning rate in early epochs helps the model learn quickly, while a lower rate in later epochs allows for fine-tuning.
Checkpointing is also commonly used to save model states at different epochs. This ensures that the best-performing version of the model is preserved, even if later epochs degrade performance.
These strategies transform epochs from a simple count into a dynamic component of the training process.
Common Pitfalls and Practical Insights
A common mistake is assuming that more epochs always lead to better results. In reality, excessive training often harms performance. Another issue is ignoring validation metrics and focusing solely on training accuracy, which can be misleading.
Successful practitioners treat epochs as part of a broader system. They combine them with proper data preprocessing, appropriate model architecture, and continuous monitoring. Visualization tools play a key role here, offering insights into how the model behaves over time.
Final Thoughts
Epochs may appear to be just a number in a training configuration, but they are far more than that. They define how your model learns, how it evolves, and ultimately how it performs in real-world scenarios.
Mastering epochs requires a shift in mindset. Instead of treating them as a fixed parameter, think of them as a learning timeline—one that you can observe, adjust, and optimize. When used correctly, epochs become a powerful tool for building models that are not only accurate but also efficient and reliable.
Kaashiv Infotech Offers, Full Stack Python Course, Data Science Course, & More, visit their website www.kaashivinfotech.com.


