
Bucket Sort in DSA – Sorting is one of the most fundamental operations in computer science. From ranking search results to organizing databases, sorting algorithms power countless systems behind the scenes. While algorithms like Merge Sort and Quick Sort are widely discussed, Bucket Sort offers a unique and powerful alternative when working with specific types of data distributions.
In this comprehensive guide, we’ll explore Bucket Sort from basic intuition to implementation strategies, complexity analysis, optimization techniques, and real-world applications.
Introduction to Bucket Sort in DSA
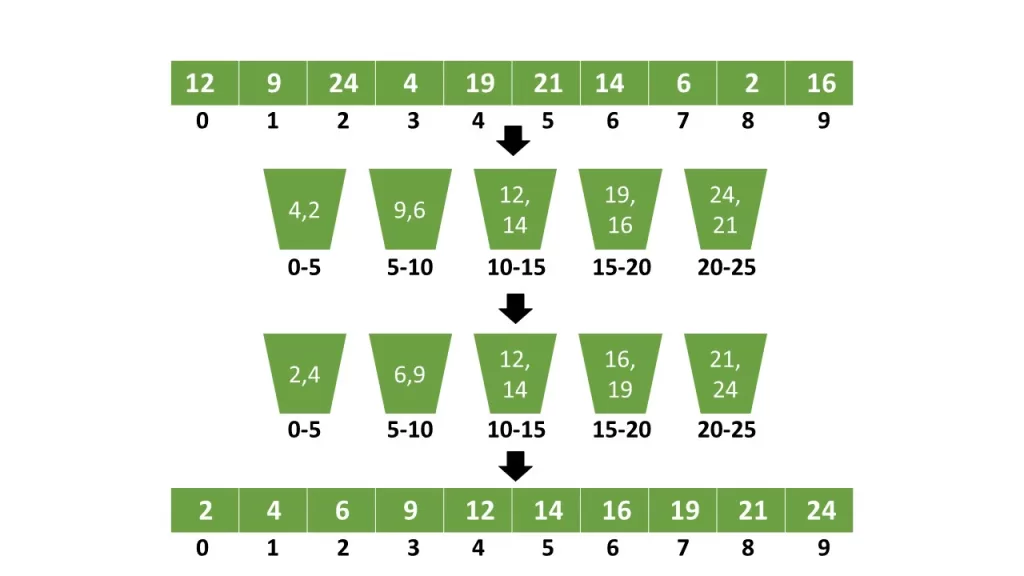
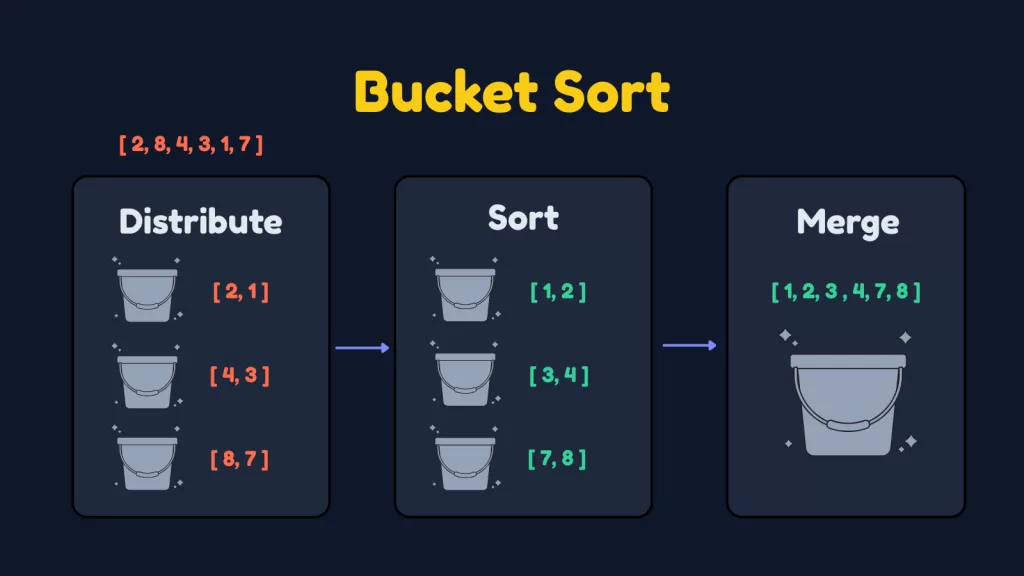
Bucket Sort is a non-comparison-based sorting algorithm that distributes elements into multiple groups called buckets. Each bucket holds elements within a specific value range. Once distributed, each bucket is sorted individually, and finally, all buckets are concatenated to produce the sorted output.
Unlike comparison-based algorithms that repeatedly compare elements, Bucket Sort uses distribution logic to reduce unnecessary comparisons.
The core philosophy is simple:
Divide the data → Sort smaller groups → Combine results.
This makes Bucket Sort particularly efficient when the input data is uniformly distributed across a known range.
Why Do We Need Bucket Sort?
Most common sorting algorithms have a lower bound of O(n log n) due to comparison-based limitations. However, in certain situations, we can break this barrier.
If:
- The input data range is known
- The values are evenly distributed
- Additional memory usage is acceptable
Then Bucket Sort can achieve near O(n) time complexity.
For example:
- Sorting decimal numbers between 0 and 1
- Sorting student marks between 0 and 100
- Sorting normalized probabilities
In such cases, distribution-based sorting can outperform comparison-based algorithms.
Core Idea Behind Bucket Sort
Imagine you have 100 students and want to rank them based on marks between 0 and 100. Instead of sorting all 100 students directly:
- Create buckets (0–9, 10–19, 20–29, etc.)
- Place each student into the appropriate bucket
- Sort students within each bucket
- Merge buckets in order
Instead of sorting 100 students at once, you sort smaller groups — significantly reducing effort if distribution is even.
Step-by-Step Working of Bucket Sort
Create Buckets
Create k empty buckets.
The number of buckets depends on:
- Input size (n)
- Range of values
- Distribution pattern
Often, k = n is used for floating-point numbers.
Distribute Elements
For each element x, compute bucket index using:index=floor(n×x)
(for values between 0 and 1)
Then insert the element into that bucket.
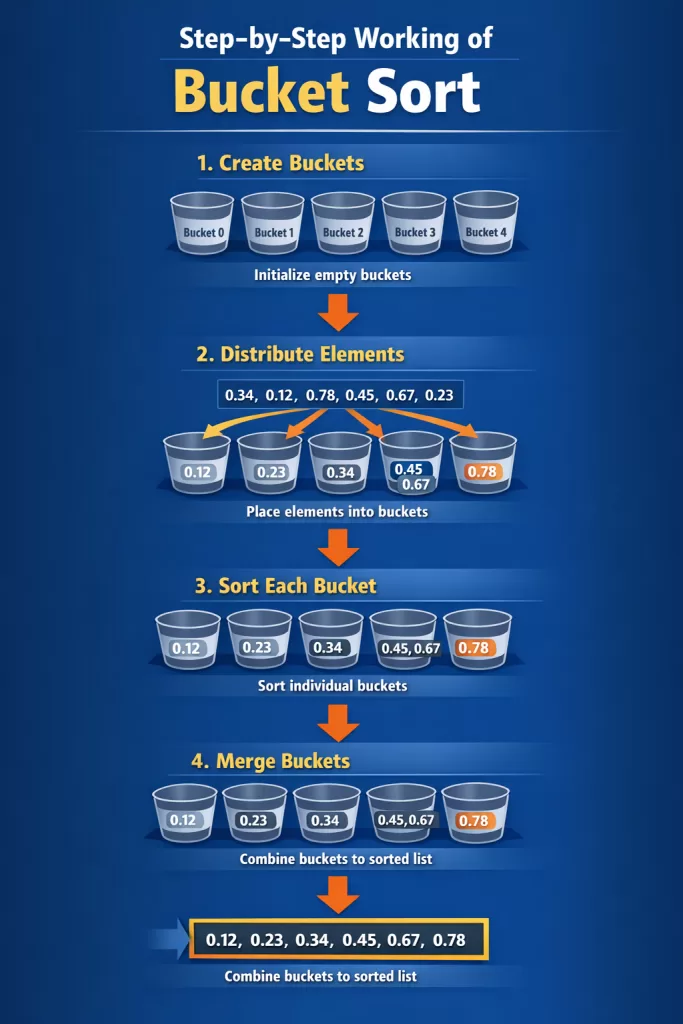
Sort Each Bucket
Each bucket is sorted individually.
Common choices include:
- Insertion Sort (efficient for small data)
- Merge Sort (if bucket size is large)
- Built-in sorting functions
Concatenate Buckets
Traverse buckets in order and combine them to form the final sorted array.
Detailed Example
Let’s sort:
[0.78, 0.12, 0.45, 0.91, 0.34, 0.56, 0.23, 0.67]
Create 8 buckets (n = 8).
Using index = int(n × value):
| Value | Bucket Index |
|---|---|
| 0.78 | 6 |
| 0.12 | 0 |
| 0.45 | 3 |
| 0.91 | 7 |
| 0.34 | 2 |
| 0.56 | 4 |
| 0.23 | 1 |
| 0.67 | 5 |
Buckets become:
B0 → [0.12]
B1 → [0.23]
B2 → [0.34]
B3 → [0.45]
B4 → [0.56]
B5 → [0.67]
B6 → [0.78]
B7 → [0.91]
After sorting individual buckets and merging:
[0.12, 0.23, 0.34, 0.45, 0.56, 0.67, 0.78, 0.91]
Algorithm (Pseudocode)
BUCKET-SORT(A):
n = length(A)
create n empty buckets for i = 0 to n-1:
insert A[i] into bucket[n * A[i]] for each bucket:
sort(bucket) concatenate all buckets into A
Python Implementation
def bucket_sort(arr):
n = len(arr)
buckets = [[] for _ in range(n)]
# Distribute elements
for value in arr:
index = int(value * n)
buckets[index].append(value)
# Sort individual buckets
for bucket in buckets:
bucket.sort()
# Merge buckets
sorted_array = []
for bucket in buckets:
sorted_array.extend(bucket)
return sorted_array
Time Complexity Analysis
Best Case (Uniform Distribution)
Each bucket contains 1 element.
Time complexity:O(n+k)
If k ≈ n:O(n)
Average Case
Elements evenly spread.O(n+k)
Worst Case
All elements go into one bucket.
Sorting that bucket takes:O(n2)
(if insertion sort is used)
Thus worst-case:O(n2)
Space Complexity
Extra memory is required for buckets.O(n+k)
Bucket Sort is not in-place.

Advantages of Bucket Sort
- Can achieve linear time
- Works well for floating-point numbers
- Easily parallelizable
- Simple and intuitive
- Efficient when data is uniformly distributed
Disadvantages of Bucket Sort in DSA
- Performance depends heavily on distribution
- Extra memory required
- Poor choice for skewed datasets
- Choosing optimal bucket size can be challenging
Bucket Sort in DSA vs Other Sorting Algorithms
| Feature | Bucket Sort | Merge Sort | Quick Sort | Counting Sort |
|---|---|---|---|---|
| Comparison Based | No | Yes | Yes | No |
| Best Case | O(n) | O(n log n) | O(n log n) | O(n+k) |
| Worst Case | O(n²) | O(n log n) | O(n²) | O(n+k) |
| Extra Space | Yes | Yes | Minimal | Yes |
| Works for Floats | Yes | Yes | Yes | No |
Choosing the Number of Buckets
Choosing k is crucial.
If k is too small:
- Buckets become crowded
- Sorting cost increases
If k is too large:
- Memory usage increases
Common strategies include:
- k = n
- k = √n
- Based on value range
Optimal selection depends on dataset characteristics.
Real-World Applications
Bucket Sort is used in:
- Floating-point number sorting
- Distributed systems
- Hash-based partitioning
- Load balancing systems
- Histogram-based grouping
- External sorting
Many large-scale systems internally use partition-based sorting similar to Bucket Sort.
Handling Integers and Negative Numbers
For integers:
- Determine minimum and maximum
- Normalize values before bucket assignment
For negative numbers:normalized=value−min
Then compute bucket index accordingly.
When Should You Use Bucket Sort?

Use Bucket Sort when:
- Input size is large
- Data is uniformly distributed
- Range is known
- Linear performance is desired
- Extra memory is acceptable
Avoid it when:
- Distribution is unknown
- Memory constraints are strict
- Dataset is highly skewed
Key Takeaways
- Bucket Sort distributes elements before sorting
- Best-case complexity can reach O(n)
- Performance depends on data distribution
- Not an in-place algorithm
- Ideal for uniform datasets
Final Thoughts
Bucket Sort in DSA is a powerful algorithm that breaks traditional comparison-sorting limitations when applied correctly. It demonstrates an important algorithmic principle:
Intelligent data distribution can significantly reduce sorting effort.
Understanding Bucket Sort in DSA strengthens your problem-solving skills and helps you choose the right algorithm for the right data scenario.
Want to learn more ??, Kaashiv Infotech Offers Data Analytics Course, Data Science Course, Cyber Security Course & More Visit Their Website www.kaashivinfotech.com.


