What is Data Preprocessing in Data Science? 7 Powerful Reasons It Matters More Than You Think 🚀

What is Data Preprocessing in Data Science? This is one of the first questions I asked when I started learning data science. At first, I thought building machine learning models was the most important part. But after working on a few projects, I realized something surprising.
What is Data Preprocessing in Data Science? Simply put, it is the process of cleaning, organizing, and transforming raw data into a format that computers and machine learning algorithms can understand.
In fact, many data scientists spend more time preparing data than building models. If the data is messy, incomplete, or inaccurate, even the most advanced algorithm will produce poor results.
In this guide, I’ll explain everything I learned about data preprocessing in data science, why it matters, and the most common techniques used in real-world projects.
📌 Key Highlights
- Learn what is Data Preprocessing in Data Science in simple words.
- Understand why data preprocessing is important.
- Discover common data cleaning techniques.
- Learn about handling missing values and duplicates.
- Understand data transformation and normalization.
- Explore real-world examples of data preprocessing.
- Learn how preprocessing improves machine learning accuracy.
What is Data Preprocessing in Data Science?
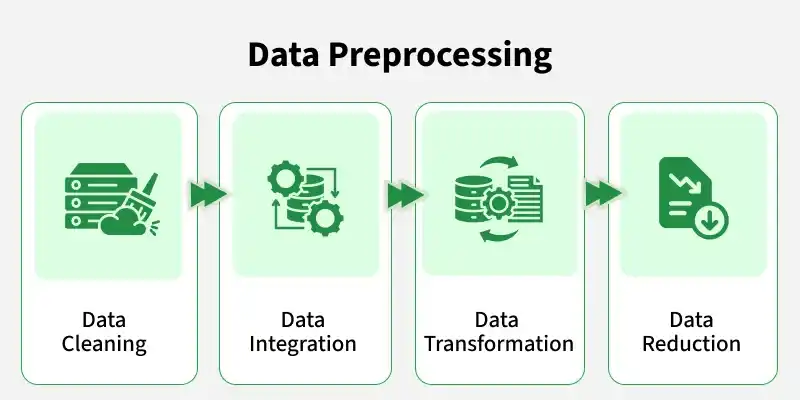
Data preprocessing in data science is the process of converting raw data into a clean, organized, and usable format before analysis or machine learning.
Raw data often contains:
- Missing values
- Duplicate records
- Incorrect entries
- Inconsistent formats
- Outliers
- Unnecessary information
Before using data for analysis, we need to clean and prepare it.
Think about receiving a spreadsheet with thousands of customer records. Some rows may have missing phone numbers. Others may contain spelling mistakes or duplicate entries.
If we use this data directly, our results may be inaccurate. That’s where data preprocessing in data science becomes essential.
Why is Data Preprocessing Important in Data Science? 🤔
I learned this lesson the hard way during one of my beginner projects.
I downloaded a dataset and immediately trained a machine learning model. The accuracy was terrible.
After inspecting the data, I discovered:
- Missing values
- Duplicate records
- Wrong date formats
Once I cleaned the dataset, the model’s performance improved significantly.
This taught me a valuable lesson:
Good data leads to good results. Bad data leads to bad decisions.
Benefits of Data Preprocessing
✅ Improves data quality
✅ Increases model accuracy
✅ Reduces errors
✅ Speeds up data analysis
✅ Helps discover meaningful insights
✅ Makes datasets consistent and reliable
Main Steps in Data Preprocessing in Data Science
The data preprocessing process usually includes several important stages.
1. Data Collection

The first step is gathering data from different sources such as:
- Databases
- APIs
- Surveys
- Websites
- Business applications
For example, an online shopping company may collect customer data from its website, mobile app, and sales system.
2. Data Cleaning
Data cleaning is one of the most important parts of data preprocessing in data science.
The goal is to identify and fix errors.
Common Data Cleaning Tasks
Removing Duplicate Data
Sometimes the same record appears multiple times.
Example:
| Customer ID | Name |
|---|---|
| 101 | John |
| 101 | John |
One of these entries should be removed.
Correcting Errors
Example:
- Chennai
- Chennnai
- CHENNAI
These should be standardized into a single format.
Fixing Inconsistent Data
Dates may appear as:
- 01/05/2025
- 2025-05-01
- May 1, 2025
Preprocessing converts them into a consistent format.
3. Handling Missing Values
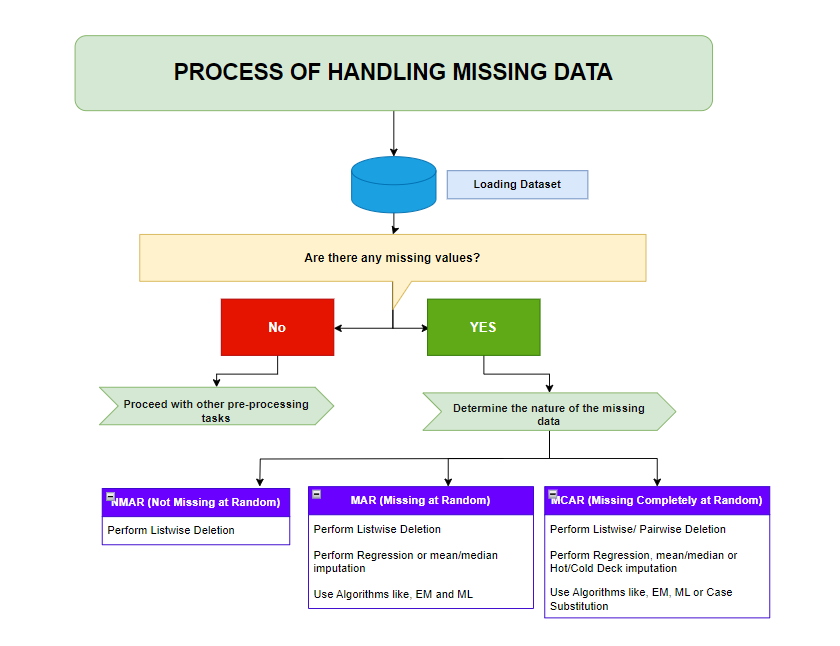
Missing values are extremely common in real-world datasets.
For example:
| Name | Age |
| Ravi | 25 |
| Priya | NULL |
The age value is missing.
Ways to Handle Missing Values
- Remove the row
- Replace with average value
- Replace with median value
- Use machine learning techniques to estimate values
Choosing the right method depends on the dataset and project requirements.
4. Data Transformation
Data transformation converts data into a suitable format.
This step helps algorithms understand the information more effectively.
Examples
Converting Text into Numbers
Machine learning algorithms work better with numerical values.
Example:
| Gender | Encoded Value |
| Male | 1 |
| Female | 0 |
Date Conversion
Converting dates into:
- Day
- Month
- Year
This makes analysis easier.
5. Data Normalization
Different columns may have different scales.
Example:
| Feature | Value |
| Salary | 50000 |
| Age | 25 |
Since salary values are much larger than age values, some algorithms may give salary more importance.
Normalization scales values into a similar range.
This improves model performance and training speed.
6. Feature Selection
Not every column is useful.
Imagine predicting house prices.
Useful features:
- Location
- Number of bedrooms
- Area
Less useful features:
- Random ID numbers
Removing unnecessary columns improves efficiency.
7. Data Reduction
Large datasets can be difficult to process.
Data reduction helps decrease data size while preserving important information.
Benefits include:
- Faster processing
- Lower storage requirements
- Better performance
Real-Life Example of Data Preprocessing in Data Science 🌍
Let’s imagine a hospital wants to predict patient readmission rates.
The dataset contains:
- Patient age
- Medical history
- Treatment records
- Admission dates
Problems found:
- Missing patient ages
- Duplicate records
- Different date formats
- Incorrect entries
Before building a predictive model, the hospital must perform data preprocessing in data science.
After cleaning and transforming the data, the hospital can generate more accurate predictions and improve patient care.
This is exactly how many real-world data science projects work.
Common Data Preprocessing Techniques
Some of the most widely used data preprocessing techniques include:
Data Cleaning
Removing errors and inconsistencies.
Data Integration
Combining data from multiple sources.
Data Transformation
Converting data into a suitable format.
Data Normalization
Scaling data values.
Feature Engineering
Creating new features from existing data.
Feature Selection
Choosing only relevant features.
These techniques help create high-quality datasets for analysis and machine learning.
Challenges in Data Preprocessing
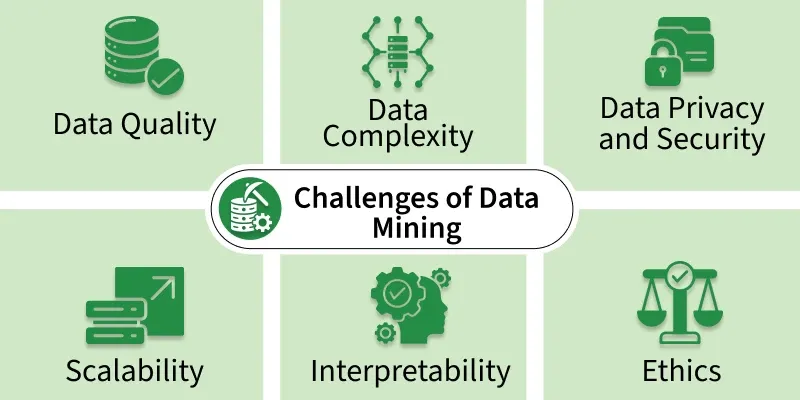
Although data preprocessing in data science is important, it can also be challenging.
Some common difficulties include:
Large Volumes of Data
Modern organizations generate huge amounts of information every day.
Missing Information
Incomplete records can affect analysis.
Inconsistent Formats
Data collected from different systems often follows different formats.
Noisy Data
Some datasets contain irrelevant or incorrect information.
Handling these challenges requires experience and careful planning.
Best Practices for Data Preprocessing ✅
Here are some practices I always try to follow:
- Understand the dataset before cleaning it.
- Check for missing values.
- Remove duplicates.
- Standardize formats.
- Document every preprocessing step.
- Validate data after cleaning.
- Use visualization tools to identify outliers.
These simple habits can save hours of troubleshooting later.
Tools Used for Data Preprocessing
Popular tools for data preprocessing in data science include:
- Python
- SQL
- Microsoft Excel
- Jupyter Notebook
- Pandas
- NumPy
- Apache Spark
For beginners, I highly recommend learning Python along with the Pandas library because it makes data cleaning much easier.
You can learn more from:
- Python Official Documentation: https://www.python.org/
- Pandas Documentation: https://pandas.pydata.org/docs/
Data Preprocessing vs Data Cleaning
Many beginners think these terms mean the same thing.
They are related but different.
| Data Cleaning | Data Preprocessing |
| Removes errors | Complete preparation process |
| Handles missing values | Includes cleaning, transformation, normalization, and feature selection |
| One step | Multiple steps |
In simple words:
Data cleaning is a part of data preprocessing.
Final Thoughts
When I first started learning data science, I was excited about machine learning models and artificial intelligence. I rarely thought about preparing data.
But over time, I realized that data preprocessing in data science is often the foundation of every successful project.
No matter how advanced your algorithm is, poor-quality data will always produce poor-quality results.
That’s why understanding what is Data Preprocessing in Data Science is one of the most important skills for every aspiring data scientist.
If you’re just starting your data science journey, focus on learning data cleaning, transformation, normalization, and feature selection. These skills will help you build more accurate models and gain deeper insights from your data.
Want to learn more ??, Kaashiv Infotech Offers Data Analytics Course, Data Science Course, Cyber Security Course & More Visit Their Website www.kaashivinfotech.com.