sqoop - Sqoop Performance Tuning - apache sqoop - sqoop tutorial - sqoop hadoop
How to transfer data between Hadoop and relational databases or mainframes in Sqoop?
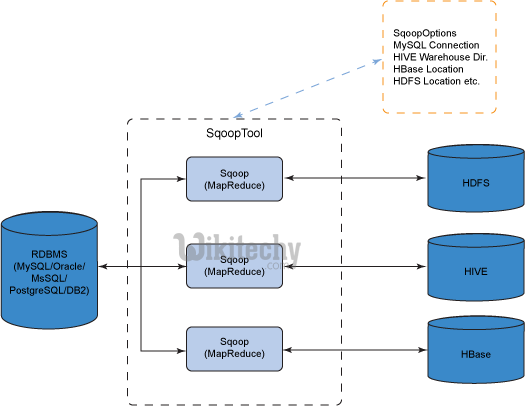
- Sqoop is a tool designed to transfer data between Hadoop and relational databases or mainframes.
- You can use Sqoop to import data from a relational database management system (RDBMS) such as MySQL or Oracle or a mainframe into the Hadoop Distributed File System (HDFS), transform the data in Hadoop MapReduce, and then export the data back into an RDBMS.
- Sqoop automates most of this process, relying on the database to describe the schema for the data to be imported.
- Sqoop uses MapReduce to import and export the data, which provides parallel operation as well as fault tolerance.
Learn sqoop - sqoop tutorial - performance tuning in sqoop - sqoop examples - sqoop programs
Sqoop Performance Tuning
- Tune the following Sqoop arguments in JDBC connection or Sqoop mapping to optimize performance
- batch
- split-by and boundary-query
- direct
- fetch-size
- num-mapper
Inserting Data in Batches
- Specifies that we can group the related SQL statements into a batch when we export data.
- The JDBC interface exposes an API for doing batches in a prepared statement with multiple sets of values.
- This API is present in all JDBC drivers because it is required by the JDBC interface.
- Enable JDBC batching using the --batch parameter.
sqoop export --connect
<<JDBC URL>> --username
<<SQOOP_USER_NAME>> --password
<<SQOOP_PASSWOR>> --table
<<TABLE_NAME>> --export-dir
<<FOLDER_URI>> --batch
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
- The second option is to use the property sqoop.export.records.per.statement to specify the number of records that will be used in each insert statement:
sqoop export
-Dsqoop.export.records.per.statement=10
--connect <<JDBC URL>> --username
<<SQOOP_USER_NAME>> --password
<<SQOOP_PASSWORD>> --table
<<TABLE_NAME>> --export-dir
<<FOLDER_URI>>
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
- Finally, you can set how many rows will be inserted per transaction with the sqoop.export.statements.per.transaction property:
sqoop export
-Dsqoop.export.statements.per.transaction=10 --connect
<<JDBC URL>> --username
<<SQOOP_USER_NAME>> --password
<<SQOOP_PASSWORD>> --table
<<TABLE_NAME>> --export-dir
<<FOLDER_URI>>
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
- The default values can vary from connector to connector. Sqoop defaults to disabled batching and to 100 for both sqoop.export.records.per.statementand sqoop.export.statements.per.transactionproperties.
Sqoop related tags : sqoop import , sqoop interview questions , sqoop export , sqoop commands , sqoop user guide , sqoop documentation
Custom Boundary Queries
- Specifies the range of values that you can import.
- You can use boundary-query if you do not get the desired results by using the split-by argument alone.
- When you configure the boundary-query argument, you must specify the min(id) and max(id) along with the table name.
- If you do not configure the argument, Sqoop runs the following query.
sqoop import --connect
<<JDBC URL>> --username
<<SQOOP_USER_NAME>> --password
<<SQOOP_PASSWORD>> --query <<QUERY>>
--split-by <<ID>>
--target-dir <<TARGET_DIR_URI>>
--boundary-query "select min(<<ID>>), max(<<ID>>)
from <<TABLE>>"
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
Importing Data Directly into Hive
- Specifies the direct import fast path when you import data from RDBMS.
- Rather than using the JDBC interface for transferring data, the direct mode delegates the job of transferring data to the native utilities provided by the database vendor.
- In the case of MySQL, the mysqldump and mysqlimport will be used for retrieving data from the database server or moving data back.
- In the case of PostgreSQL, Sqoop will take advantage of the pg_dump utility to import data. Using native utilities will greatly improve performance, as they are optimized to provide the best possible transfer speed while putting less burden on the database server.
- There are several limitations that come with this faster import.
- For one, not all databases have available native utilities.
- This mode is not available for every supported database.
- Out of the box, Sqoop has direct support only for MySQL and PostgreSQL.
sqoop import --connect
<<JDBC URL>> --username
<<SQOOP_USER_NAME>> --password
<<SQOOP_PASSWORD>> --table
<<TABLE_NAME>> --direct
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
Importing Data using Fetch-size
- Specifies the number of entries that Sqoop can import at a time.
syntax
--fetch-size=<n>
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
- Where
represents the number of entries that Sqoop must fetch at a time. Default is 1000. - Increase the value of the fetch-size argument based on the volume of data that need to read.
- Set the value based on the available memory and bandwidth.
Controlling Parallelism
- Specifies number of map tasks that can run in parallel. Default is 4.
- To optimize performance, set the number of map tasks to a value lower than the maximum number of connections that the database supports.
- Use the parameter --num-mappers if you want Sqoop to use a different number of mappers.
- For example, to suggest 10 concurrent tasks, use the following Sqoop command:
sqoop import --connect
jdbc:mysql://mysql.example.com/sqoop --username
sqoop --password
sqoop --table
cities --num-mappers 10
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
- Controlling the amount of parallelism that Sqoop will use to transfer data is the main way to control the load on your database.
- Using more mappers will lead to a higher number of concurrent data transfer tasks, which can result in faster job completion.
- However, it will also increase the load on the database as Sqoop will execute more concurrent queries.
Split-By
- Specifies the column name based on which Sqoop must split the work units.
syntax
--split-by <column name>
sqoop import --connect
<<JDBC URL>> --username
<<SQOOP_USER_NAME>> --password
<<SQOOP_PASSWORD>> --query <<QUERY>>
--split-by <<ID>>
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
Note:
If you do not specify a column name, Sqoop splits the work units based on the primary key.