
If you’ve ever asked yourself “What is PyTorch, and why is everyone in AI obsessed with it?” — you’re not alone.
We’re living in a fascinating time. Programming languages like C and C++—created decades ago—are still relevant today. But in contrast, PyTorch, which was released in 2016, rose from a research tool to the global standard for artificial intelligence in just a few years. That kind of growth is rare, even in tech.
Machine learning is no longer just a trendy buzzword. It has quietly become the backbone of almost everything futuristic we interact with today. From self-driving cars and intelligent voice assistants to AI-generated images, medical diagnosis systems, and large language models like ChatGPT — all of it depends on deep learning.
And at the center of this revolution sits one powerful framework: PyTorch in Python.
By 2025, nearly 68% of AI researchers preferred PyTorch over TensorFlow, and in 2026, its dominance has only become stronger. Whether you explore academic research papers, Kaggle competitions, startup prototypes, or production-grade AI systems, PyTorch appears everywhere.
Imagine a student building their first neural network late at night, a researcher testing a new NLP model, or a startup fine-tuning a custom LLM for their product. Despite their different goals, they’re all connected by one thing — PyTorch.
By the end of this guide, you’ll not only understand what PyTorch is, but also why it has become the most important deep learning skill you can learn today.
🧠 What Is PyTorch?

Let’s break it down in the simplest way possible.
PyTorch is an open-source deep learning framework built using Python that allows developers to create and train neural networks with ease. But that definition alone doesn’t capture why it’s so popular.
What really makes PyTorch special is how natural it feels. Instead of forcing you to learn a completely new system, it works almost like regular Python code. That means when you write PyTorch programs, it feels intuitive rather than overwhelming.
This is exactly why beginners don’t feel lost, and experienced developers don’t feel restricted.
🧠 The Magic of Dynamic Computation Graphs
One of the biggest reasons behind PyTorch’s success is something called a dynamic computation graph.
In simple terms, the neural network structure is created as your code runs, not beforehand.
This might sound like a small technical detail, but it changes everything.
It means you can modify your model while it’s running, experiment freely, and debug your code step-by-step just like you would in a normal Python program. There’s no rigid structure locking you in, no complicated sessions to manage, and no unnecessary friction between your idea and implementation.
For researchers and developers who constantly experiment, this flexibility is incredibly powerful.
🧪 A Tiny Example That Explains Everything
Here’s a simple PyTorch example:
import torch
x = torch.tensor([2.0, 3.0])
y = torch.tensor([4.0, 1.0])
z = x + y
print(z)At first glance, this looks just like NumPy code. And that’s exactly the point.
PyTorch tensors behave like NumPy arrays, but with a major upgrade — they can run on GPUs. This makes computations significantly faster, which is essential for training deep learning models.
A good way to think about it is this: if NumPy had superpowers, it would look exactly like PyTorch.
🎯 Who Should Learn PyTorch in 2026?

If you’re wondering whether PyTorch is worth learning, the honest answer is simple — yes, especially if you’re interested in AI.
Students entering the world of machine learning will find PyTorch to be the most approachable starting point. Its simplicity allows them to focus on understanding concepts instead of struggling with complex tools.
For Python developers, PyTorch offers one of the smoothest transitions into AI. Since it follows Python’s natural style, the learning curve is much shorter than expected.
Researchers across the globe rely heavily on PyTorch because it allows them to quickly test new ideas and publish results without unnecessary complexity.
Data scientists also benefit from PyTorch when working on advanced problems like natural language processing or computer vision, where traditional tools fall short.
And if you’re someone building modern AI systems like chatbots, recommendation engines, or LLM-based applications, PyTorch is almost unavoidable.
🚀 Why PyTorch Became So Popular
PyTorch wasn’t always the leader. In fact, between 2015 and 2017, TensorFlow dominated the AI ecosystem.
So what changed?
The answer lies in developer experience.
PyTorch feels like writing normal Python code. This might sound simple, but it eliminates a huge mental barrier for developers. Instead of adapting to the framework, the framework adapts to you.
Debugging is another major advantage. With PyTorch, you can use standard Python tools like print statements and breakpoints. This makes it much easier to identify issues and fix them quickly.
Another key factor is experimentation speed. In research and AI development, the ability to quickly test ideas is crucial. PyTorch enables rapid prototyping, which is why researchers adopted it so quickly.
Finally, PyTorch became the backbone of modern breakthroughs in generative AI. From transformers and diffusion models to reinforcement learning systems, most cutting-edge innovations rely on PyTorch.
⚔️ PyTorch vs TensorFlow in 2026

The debate between PyTorch and TensorFlow has existed for years, but in 2026, the difference is clearer than ever.
PyTorch dominates when it comes to research, experimentation, and modern AI systems like LLMs and generative models. Its flexibility and ease of use make it the preferred choice for developers who want full control.
TensorFlow, on the other hand, still holds strength in large-scale enterprise deployments and mobile applications. It also has better support for Google’s TPU hardware.
However, even in organizations where TensorFlow is used for production, PyTorch is often the starting point for research and prototyping.
So the practical advice is straightforward: start with PyTorch, and then learn TensorFlow if your work specifically requires it.
📚 The Story Behind PyTorch
PyTorch was created by Facebook AI Research (FAIR) in 2016.
At that time, researchers were frustrated with rigid frameworks that made experimentation difficult. They needed something flexible, easy to debug, and closely aligned with Python.
PyTorch was built to solve exactly that problem.
Within a couple of years, it gained massive popularity in the research community. By 2019, it had already become the default choice for many academic papers. Fast forward to 2026, and it now powers some of the most advanced AI systems in the world.
💼 Why PyTorch Matters for Your Career
If you’re serious about building a career in AI, PyTorch is not optional — it’s essential.
Most modern AI roles, especially those involving deep learning, NLP, or computer vision, expect familiarity with PyTorch. It’s widely used in startups, research labs, and even large tech companies.
The demand is reflected in salaries as well. In India, AI engineers with PyTorch skills can earn anywhere between ₹12 LPA to ₹45 LPA depending on experience. Globally, salaries often range from $110,000 to over $200,000.
But beyond salary, PyTorch gives you something more valuable — the ability to build real AI systems.
🧩 Understanding How PyTorch Works
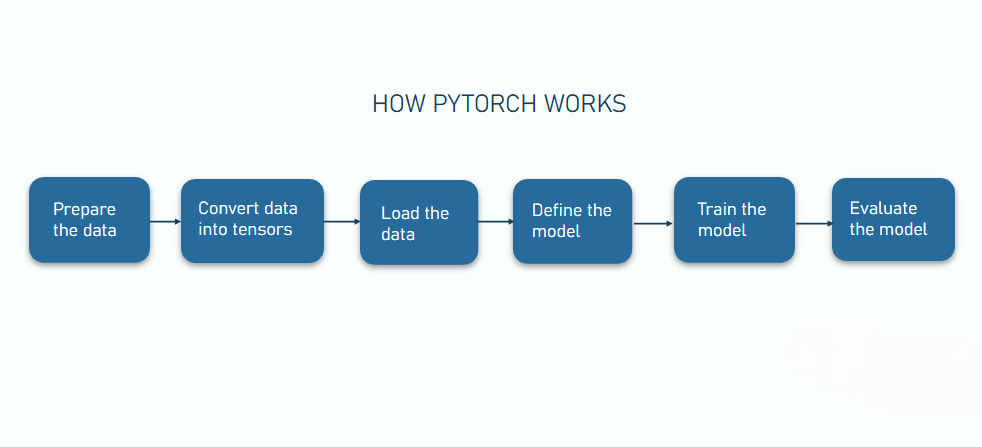
At its core, PyTorch is built around a few key ideas that work together seamlessly.
Everything starts with tensors, which are essentially data structures similar to arrays but optimized for deep learning. These tensors flow through a neural network defined using modules, where each layer transforms the data.
As the model makes predictions, a loss function measures how far the output is from the expected result. PyTorch’s autograd system then automatically calculates gradients, allowing the optimizer to adjust the model’s parameters.
This entire cycle repeats during training, gradually improving the model’s performance.
What makes PyTorch unique is how transparent this process is. You’re not just calling functions — you’re actually understanding what’s happening under the hood.
🌍 Real-World Impact of PyTorch
PyTorch isn’t limited to tutorials or experiments. It’s actively used in real-world systems across industries.
In healthcare, it powers models that analyze medical images and assist in disease detection. In autonomous vehicles, it helps systems understand their surroundings and make driving decisions.
In natural language processing, PyTorch is the foundation for chatbots, translation tools, and large language models. In robotics, it enables reinforcement learning systems that learn from interaction.
And perhaps most visibly, in generative AI, PyTorch drives technologies like image generation, video synthesis, and voice cloning.
⚡ Performance and Hardware
Training AI models requires significant computational power, and PyTorch makes it surprisingly accessible.
With just a single line of code, you can move your model to a GPU and accelerate training dramatically. It also supports modern hardware like Apple Silicon and allows distributed training across multiple GPUs.
This flexibility ensures that both beginners and advanced users can scale their projects based on their needs.
🧭 Your Learning Path in 2026
Learning PyTorch doesn’t have to be complicated.
It usually starts with understanding Python and basic data handling. From there, you move into tensors and simple neural networks, followed by training loops and optimization.
As you grow, you explore more advanced topics like convolutional networks, transformers, and deployment techniques.
The key is consistency. Even a few weeks of focused learning can give you a strong foundation.
🔥 Final Thoughts
PyTorch is more than just a framework. It represents a shift in how AI is built — making it more accessible, flexible, and powerful.
You don’t need a PhD to get started. You don’t need to be a math genius. What you need is curiosity and the willingness to experiment.
Start with a simple model. Break things. Fix them. Build again.
Because in the world of AI, learning doesn’t come from reading — it comes from building.
And your journey starts with one line of PyTorch code.
Want to Learn More About Python & Artificial Intelligence ???, Kaashiv Infotech Offers Full Stack Python Course, Artificial Intelligence Course, Data Science Course & More Visit Their Website course.kaashivinfotech.com.


