apache hive - Hadoop Hive - Hive Hadoop- hive tutorial - hadoop hive - hadoop hive - hiveql
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
The Hive Shell
hive> SHOW TABLES; OK Time taken: 10.425 seconds
% hive -f script.q
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
RUNNING HIVE
export HADOOP_HOME= <hadoop-install-dir>
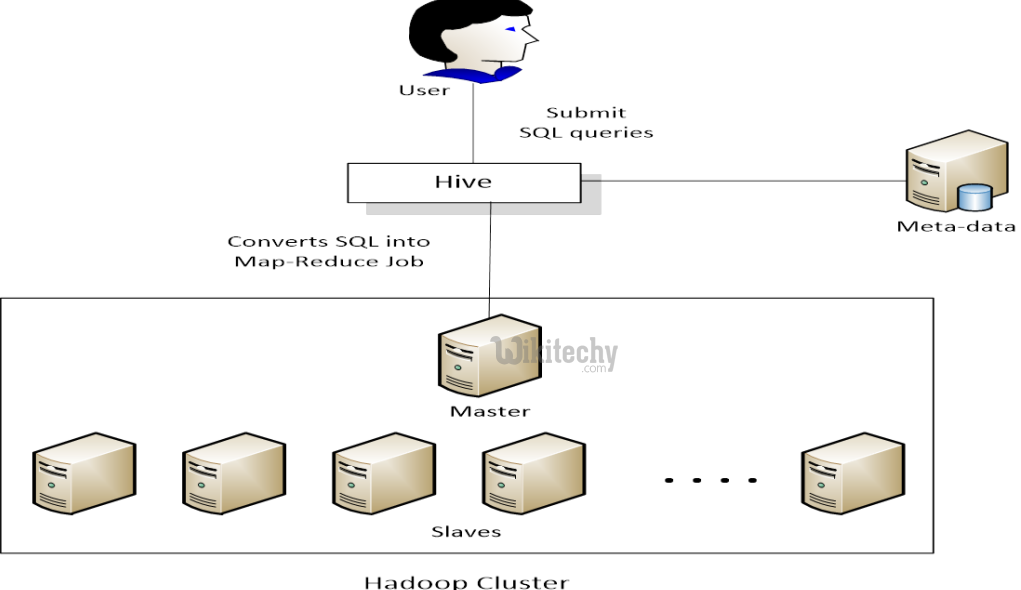
learn hive - hive tutorial - apache hive - Apache Hive - hive sql query flow mapreduce hadoop - hive examples
$ <hadoop-directory>/bin/hadoop fs -mkdir /tmp
$ <hadoop-directory>/bin/hadoop fs -mkdir /user/hive/warehouse
$ <hadoop-directory>/bin/hadoop fs -chmod g+w /tmp
$ <hadoop-directory>/hadoop fs -chmod g+w /user/hive/warehouse
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
RUNNING HCATALOG
$HIVE_HOME/hcatalog/sbin/hcat_server.sh
RUNNING WEBHCat (Templeton)
$HIVE_HOME/hcatalog/sbin/webhcat_server.sh
CONFIGURATION
HIVE_CONF_DIR
<install-dir>/conf/hive-site.xml.
Log4j configuration is stored in
<install-dir>/conf/hive-log4j.properties
RUNTIME CONFIGURATION
hive> SET mapred.job.tracker=myhost.mycompany.com:50030;
hive> SET -v;
HIVE, MAP-REDUCE AND LOCAL-MODE
mapred.job.tracker
hive> SET mapred.job.tracker=local
hive> SET mapred.job.tracker = local
ERROR LOGS
/tmp/<user.name>/hive.log