apache hive - Hive Partitioning - hive tutorial - hadoop hive - hadoop hive - hiveql
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
What is Partitioning?
- A partition is a logical division of a hard disk that is treated as a separate unit by operating systems (OS) and file systems.
- The OS and file systems can manage information on each partition as if it were a distinct hard drive.
- This permits the drive to operate as several smaller sections to improve efficiency, although it reduces usable space on the hard disk because of additional overhead from multiple OS.
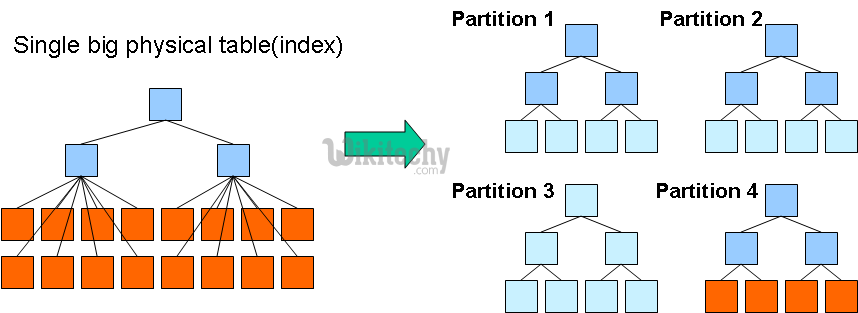
apache hive - learn hive - hive tutorial - hive partitioning - hive example
Hive Partitioning
- Hive categorizes tables into partitions. It is a way of dividing a table into related parts based on the values of partitioned columns such as date, city, and department.
- By means of partition, it is easy to query a portion of the data.
- Tables or partitions are sub-divided into buckets, to provide extra structure to the data that may be used for more efficient querying.
- Bucketing works based on the value of hash function of some column of a table.
- For instance, a table named wikitechy_table contains employee data such as id, name, dept, and year of joining.
- Suppose you want to recover the details of all wikitechy_employees who joined in 2016. A query searches the whole table for the required information.
- Still, if you partition the wikitechy_employee data with the year and store it in a separate file, it reduces the query processing time.
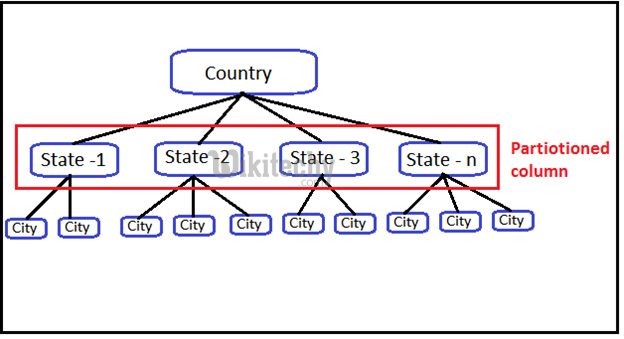
apache hive - learn hive - hive tutorial - hive partitions - hive example
How to partition a file and its data:
- The following file contains wikitechy_employee data table.
- / wikitechy_table / wikitechy_employee/file1
id, name, dept, yoj
1, Anu, TP, 2016
2, Bastin, HR, 2016
3, Kavin,SC, 2017
4, Princy, SC, 2017
- The above data is partitioned into two files using year.
- / wikitechy_table / wikitechy_employee/2016/file2
1, Anu, TP, 2016
2, Bastin, HR, 2016
- / wikitechy_table / wikitechy_employee/2017/file3
3, Kavin,SC, 2017
4, Princy, SC, 2017
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Adding a Partition
- You can add partitions to a table by altering the table.
- Let us assume we have a table called wikitechy_employee with fields such as Id, Name, Salary, Designation, Dept, and year of joining.
Syntax
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec
[LOCATION 'location1'] partition_spec [LOCATION 'location2'] ...;
partition_spec:
: (p_column = p_col_value, p_column = p_col_value, ...)
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- The following query is used to add a partition to the wikitechy_employee table.
hive> ALTER TABLE wikitechy_employee
> ADD PARTITION (year=’2017’)
> location '/2016/part2016';
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Renaming a Partition
syntax
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- The following query is used to rename a partition:
hive> ALTER TABLE wikitechy_employee PARTITION (year=’1207’)
> RENAME TO PARTITION (Year of joining=’1207’);
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Dropping a Partition
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
syntax
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec, PARTITION partition_spec,...;
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- The following query is used to drop a partition:
hive> ALTER TABLE wikitechy_employee DROP [IF EXISTS]
> PARTITION (year=’1207’);
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Advantages
- Partitioning is used for distributing execution load horizontally.
- As the data is stored as slices/parts, query response time is faster to process the small part of the data instead of looking for a search in the entire data set.
- For instance, In a large user table where the table is partitioned by country, then selecting users of country ‘IN’ will just scan one directory ‘country=IN’ instead of all the directories.
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Limitations
- Having too many partitions in table creates large number of files and directories in HDFS, which is an overhead to NameNode since it must keep all metadata for the file system in memory only.
- Partitions may optimize some queries based on Where clauses, but may be less responsive for other important queries on grouping clauses.
- In Mapreduce processing, Huge number of partitions will lead to huge no of tasks (which will run in separate JVM) in each mapreduce job, thus creates lot of overhead in maintaining JVM start up and tear down.
- For small files, a separate task will be used for each file. In worst scenarios, the overhead of JVM start up and tear down can exceed the actual processing time.
Wikitechy Apache Hive tutorials provides you the base of all the following topics . Enjoy learning on big data , hadoop , data analytics , big data analytics , mapreduce , hadoop tutorial , what is hadoop , big data hadoop , apache hadoop , apache hive , hadoop wiki , hadoop jobs , hadoop training , hive tutorial , hadoop big data , hadoop architecture , hadoop certification , hadoop ecosystem , hadoop fs , apache pig , hadoop cluster , cloudera hadoop , hadoop download , hadoop mapreduce , hadoop workflow , hive data types , hadoop hive , pig hadoop , hadoop administration , hadoop installation , hive hadoop , learn hadoop , hadoop for dummies , hadoop commands , hive definition , hiveql , learnhive , hive sql , hive database , hive date functions , hive query , apache hive tutorial , hive apache , hive wiki , what is a hive , hive big data , programming hive , what is hive in hadoop , hive documentation , how does hive work
World's No 1 Animated self learning Website with Informative tutorials explaining the code and the choices behind it all.
© 2016 - 2026 KaaShiv InfoTech, All rights reserved. Powered by Inplant Training in chennai | Internship in chennai