apache hive - Hive Installation - hive tutorial - hadoop hive - hadoop hive - hiveql
How to Install Hive ?
- Hence, all Hadoop sub-projects which is given support Linux operating system such as Hive, Pig, and HBase
- Therefore, you need to install any Linux flavored OS.
The following simple steps are executed for Hive installation:
Step 1: Verifying JAVA Installation
- Java must be installed on your system before installing Hive.
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Sample Code
$ java -version
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- If Java is already installed in the system, you get the following output:
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Output
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
- If java is not installed in the system, then we need to follow some steps which is given below for installing java.
Steps to Install Java
Step 1:
- Download java (JDK <latest version> - X64.tar.gz)
- Then jdk-7u71-linux-x64.tar.gz will be downloaded onto your system.
Step 2:
- Generally we will able to find the downloaded java file in the Downloads folder.
- Verify the file and then extract the file jdk-7u71-linux-x64.gz by using the following commands.
Sample Code
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gz
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Step 3:
- We need to move to the location “/usr/local/” to make java available to all the users. Open root, and type the following commands.
Sample Code
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exit
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Step 4:
- For setting up these variables PATH and JAVA_HOME, add the following commands to ~/.bashrc file.
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Sample Code
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=$PATH:$JAVA_HOME/bin
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- Now apply all the changes into the current running system.
$ source ~/.bashrc
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Step 5:
- Use the following commands to configure java alternatives:
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Sample Code
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jar
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Now verify the installation using the command java -version from the terminal which is given
Step 2: Verifying Hadoop Installation
- Hadoop must be installed on your system before installing Hive. Let us verify the Hadoop installation using the following command:
$ hadoop version
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- If Hadoop is already installed in the system, then you will get the following output:
Output:
Hadoop 2.4.1 Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4
- If Hadoop is not installed on your system, then proceed with the following steps:
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Downloading Hadoop
- Download and extract Hadoop 2.4.1 from Apache Software Foundation using the following commands.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exitClicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Steps to Install Hadoop in Pseudo Distributed Mode
Step 1: Setting up Hadoop
- We can set up the Hadoop environment variables by appending the following commands to ~/.bashrc file.
Sample Code
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export
PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- Now apply all the changes into the current running system.
$ source ~/.bashrc
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Step 2: Hadoop Configuration
- We can find all the Hadoop configuration files in the location “$HADOOP_HOME/etc/hadoop” which is given
- We need to make some changes in those configuration files according to the Hadoop infrastructure.
$ cd $HADOOP_HOME/etc/hadoop
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- In order to develop Hadoop programs using java, you have to reset the java environment variables in hadoop-env.sh file by replacing JAVA_HOME value with the location of java in your system.
export JAVA_HOME=/usr/local/jdk1.7.0_71
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- Below are some lists of files that have to be edit to configure Hadoop
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
core-site.xml
- The core-site.xml file contains some information such as the port number, memory, memory limit, and the size of Read/Write buffers.
- Open the core-site.xml and add properties in between the >configuration< and >/configuration< tags in the file.
Sample Code
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
hdfs-site.xml
- The hdfs-site.xml file contains some information such as the value of replication data, the namenode path, and the datanode path of thelocal file systems.
- It means the place where we want to store the Hadoop infrastructure.
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Sample Code
dfs.replication (data replication value) = 1
(In the following path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeClicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- Open this file and add properties in between the >/configuration< and >/configuration< tags in this file.
Sample Code
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value >
</property>
</configuration>
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Note:
- In the file which is mentioned above, all the property values are user-defined and we can make changes according to the Hadoop infrastructure.
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
yarn-site.xml
- This file yarn-site.xml is used to configure yarn into Hadoop.
- Open the yarn-site.xml file and add properties in between the >/configuration< and >/configuration< tags given in this file.
Sample Code
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
mapred-site.xml
- This file mapred-site.xml is used to specify which MapReduce framework which we are using for this file
- We need to copy the file from template to mapred-site.xml file using the following command.
$ cp mapred-site.xml.template mapred-site.xml
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- Open mapred-site.xml file and add properties in between the >/configuration< and >/configuration< tags done in this file.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Verify Hadoop Installation
- The following steps are used to verify the Hadoop installation.
Step 1: Name Node Setup
- Set up the namenode by using the command “hdfs namenode -format” which is given
$ cd ~
$ hdfs namenode -format
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Output:
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/
Step 2: Verifying Hadoop dfs
- The command which is given below is used to start dfs.
$ start-dfs.sh
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Output:
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]
Step 3: Verifying Yarn Script
- The following command is used to start the yarn script. Executing this command will start your yarn daemons.
Sample Code
$ start-yarn.sh
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Output:
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Step 4: Accessing Hadoop on Browser
- The default port number to access Hadoop is 50070. Use the following url to get Hadoop services on your browser.
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Sample Code
http://localhost:50070/
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Output:
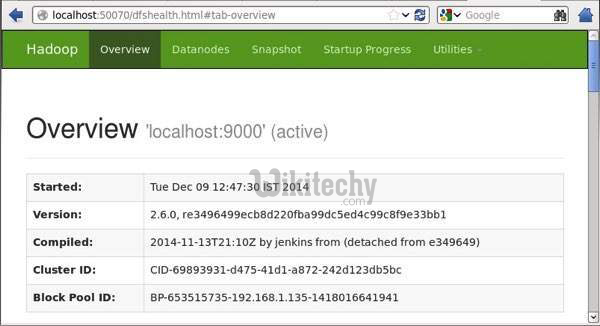
apache hive - learn hive - hive tutorial - hadoop browser - hive example
Step 5: Verify all applications for cluster
- The default port number given access to all applications of cluster is 8088.
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Sample Code
http://localhost:8088/
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Output:
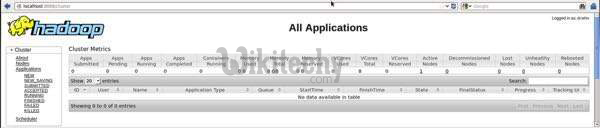
apache hive - learn hive - hive tutorial - applications cluster- hive example
Step 3: Downloading Hive
- We use hive-0.14.0 in this tutorial.
- Let us assume it gets downloaded onto the /Downloads directory. Here, we download Hive archive named “apache-hive-0.14.0-bin.tar.gz” for this tutorial.
- The following command is used to verify the download:
Sample Code
$ cd Downloads
$ lsClicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Output:
apache-hive-0.14.0-bin.tar.gz
Step 4: Installing Hive
- The following steps are required for installing Hive on your system.
- Let us extract and verify the Hive archive which is downloaded in the /Downloads directory.
Extracting and verifying Hive Archive
- The following command is used to verify the download and extract the hive archive:
$ tar zxvf apache-hive-0.14.0-bin.tar.gz
$ ls
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Output
apache-hive-0.14.0-bin apache-hive-0.14.0-bin.tar.gz
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Copying files to /usr/local/hive directory
- We need to copy the files from the super user “su -”.
- The commands which are given below used to copy the files from the extracted directory to the “/usr/local/hive” directory.
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
sample code
$ su -
passwd:
# cd /home/user/Download
# mv apache-hive-0.14.0-bin /usr/local/hive
# exit
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Setting up environment for Hive
- We can set up the Hive environment by appending the lines which are given below to ~/.bashrc file:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- The following command is used to execute ~/.bashrc file.
$ source ~/.bashrc
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Step 5: Configuring Hive
- We need to edit the hive-env.sh file, which is placed in the $HIVE_HOME/conf directory in order to configure Hive with Hadoop
- The commands redirect to Hive config folder and copy the template file:
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- Edit the hive-env.sh file by appending the following line:
export HADOOP_HOME=/usr/local/hadoop
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- Hence, Hive installation has been completed successfully.
- Now we require an external database server in order to configure Metastore. We can use Apache Derby database.
Step 6: Downloading and Installing Apache Derby
- Follow the steps given below to download and install Apache Derby:
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Downloading Apache Derby
- The following command is used to download Apache Derby. It takes some time to download.
$ cd ~
$ wget http://archive.apache.org/dist/db/derby/db-derby-10.4.2.0/db-derby-10.4.2.0-bin.tar.gz
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- The command which is given below is used to verify the download:
$ ls
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
db-derby-10.4.2.0-bin.tar.gz
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Extracting and verifying Derby archive
- The following commands are used for extracting and verifying the Derby archive:
$ tar zxvf db-derby-10.4.2.0-bin.tar.gz
$ ls
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Output:
db-derby-10.4.2.0-bin db-derby-10.4.2.0-bin.tar.gz
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Copying files to /usr/local/derby directory
- We need to copy from the super user “su -”. The following commands are used to copy the files from the extracted directory to the /usr/local/derby directory:
$ su -
passwd:
# cd /home/user
# mv db-derby-10.4.2.0-bin /usr/local/derby
# exit
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Setting up environment for Derby
- You can set up the Derby environment by appending the following lines to ~/.bashrc file:
export DERBY_HOME=/usr/local/derby
export PATH=$PATH:$DERBY_HOME/bin
Apache Hive
18
export CLASSPATH=$CLASSPATH:$DERBY_HOME/lib/derby.jar:$DERBY_HOME/lib/derbytools.jar
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- The following command is used to execute ~/.bashrc file:
$ source ~/.bashrc
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Create a directory to store Metastore
- Create a directory named data in $DERBY_HOME directory to store Metastore data.
$ mkdir $DERBY_HOME/data
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- Derby installation and environmental setup is now complete.
Step 7: Configuring Metastore of Hive
- Configuring Metastore means specifying to Hive where the database is stored.
- You can do this by editing the hive-site.xml file, which is in the $HIVE_HOME/conf directory.
- First of all, copy the template file using the following command:
$ cd $HIVE_HOME/conf
$ cp hive-default.xml.template hive-site.xml
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- Edit hive-site.xml and give the following code of lines between the
and tags:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby://localhost:1527/metastore_db;create=true </value>
<description>JDBC connect string for a JDBC metastore </description>
</property>
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- Create a file called jpox.properties and add the following lines which is given:
Jpox.Properties
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Sample Code
javax.jdo.PersistenceManagerFactoryClass =
org.jpox.PersistenceManagerFactoryImpl
org.jpox.autoCreateSchema = false
org.jpox.validateTables = false
org.jpox.validateColumns = false
org.jpox.validateConstraints = false
org.jpox.storeManagerType = rdbms
org.jpox.autoCreateSchema = true
org.jpox.autoStartMechanismMode = checked
org.jpox.transactionIsolation = read_committed
javax.jdo.option.DetachAllOnCommit = true
javax.jdo.option.NontransactionalRead = true
javax.jdo.option.ConnectionDriverName = org.apache.derby.jdbc.ClientDriver
javax.jdo.option.ConnectionURL = jdbc:derby://hadoop1:1527/metastore_db;create = true
javax.jdo.option.ConnectionUserName = APP
javax.jdo.option.ConnectionPassword = mine
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Step 8: Verifying Hive Installation
- Before running Hive, you need to create the /tmp folder and a separate Hive folder in HDFS. Here, we use the /user/hive/warehouse folder.
- You need to set write permission for these newly created folders as shown below:
chmod g+w
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- Now set them in HDFS before verifying Hive. Use the following commands:
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- The following commands are used to verify Hive installation:
$ cd $HIVE_HOME
$ bin/hive
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Logging initialized using configuration in jar:file:/home/hadoop/hive-0.9.0/lib/hive-common-0.9.0.jar!/hive-log4j.properties
Hive history file=/tmp/hadoop/hive_job_log_hadoop_201312121621_1494929084.txt
………………….
hive>
- The following sample command is executed to display all the tables:
hive> show tables;
OK
OK
Time taken: 2.798 seconds
hive>