apache hive - What is hive - hive tutorial - hadoop hive - hadoop hive - hiveql
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
What is HIVE
- Apache Hive is a component of Hortonworks Data Platform(HDP). apache hive provides a SQL-like interface to data stored in HDP.
- In a simplified defintion, apache hive is nothing but a system for managing and querying structured data built on top of Hadoop
- Map-Reduce for execution
- HDFS for storage
- Metadata on raw files
- We used Pig, which is a scripting language with a focus on dataflows.
- apache hive provides a database query interface to Apache Hadoop.

learn hive - hive tutorial - apache hive - The SQL Interface to Hadoop - hive examples
Hive: The SQL Interface to Hadoop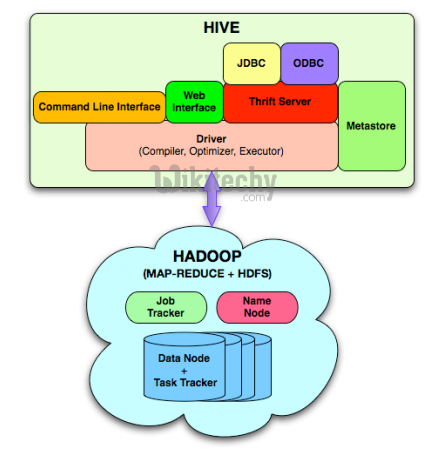
apache hive - learn hive - hive tutorial - hive architecture - hive example
- SQL as a familiar data warehousing tool
- Extensibility – Types, Functions, Formats, Scripts
- Scalability and Performance
Why to use apache hive?
- People frequently ask why do Pig and Hive exist when they look to do much of the same thing.
- Apache hive because of its SQL like query language is often used as the interface to an Apache Hadoop based data warehouse.
- Apache hive is considered friendlier and more familiar to users who are used to using SQL for querying data.
- Pig fits in through its data flow strengths where it takes on the tasks of bringing data into Apache Hadoop and working with it to get it into the form for querying.
Apache hive is not
- Not a relational database
- Not a design for OnLine Transaction Processing (OLTP)
- Not a language for real-time queries and row-level updates
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
When to use Apache hive?
- It provides us data warehousing facilities on top of an existing Hadoop cluster.
- Along with that it provides an SQL like interface which makes your work easier, in case you are coming from an SQL background.
- You can create tables in Apache hive and store data there.
- Along with that you can even map your existing HBase tables to Apache hive and operate on them.
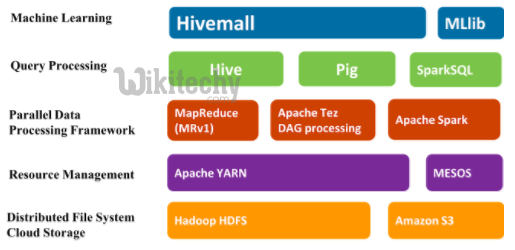
learn hive - hive tutorial - apache hive - bigdata architecture - hive examples
Features
- Apache Hive supports analysis of large datasets stored in Hadoop's HDFS and compatible file systems such as Amazon S3 filesystem.
- It provides an SQL-like query language called HiveQL with schema on read and transparently converts queries to MapReduce, Apache Tez and Spark jobs.
- All three execution engines can run in Hadoop YARN. To accelerate queries, it provides indexes, including bitmap indexes.
- Other features of Apache hive include:Indexing to provide acceleration, index type including compaction and bitmap index as of 0.10, more index types are planned.
- Different storage types such as plain text, RCFile, HBase, ORC, and others.
- Metadata storage in a relational database management system, significantly reducing the time to perform semantic checks during query execution.
- Operating on compressed data stored into the Hadoop ecosystem using algorithms including DEFLATE, BWT, snappy, etc.
- Built-in user-defined functions (UDFs) to manipulate dates, strings, and other data-mining tools. Apache hive supports extending the UDF set to handle use-cases not supported by built-in functions.
- SQL-like queries (HiveQL), which are implicitly converted into MapReduce or Tez, or Spark jobs.
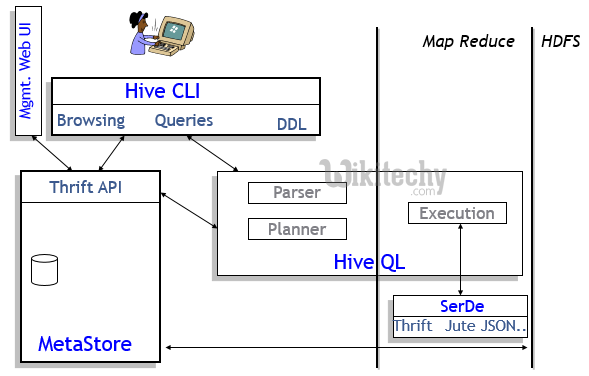
learn hive - hive tutorial - apache hive - Apache Hive Components - hive examples
- By default, Apache hive stores metadata in an embedded Apache Derby database, and other client/server databases like MySQL can optionally be used.
- The first four file formats supported in Apache hive were
- plain text,
- sequence file,
- optimized row columnar (ORC) format and
- RCFile.
- Apache Parquet can be read through plugin in versions later than 0.10 and natively starting at 0.13.
- Additional Apache hive plugins support querying of the Bitcoin Blockchain.
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Apache hive Data Models
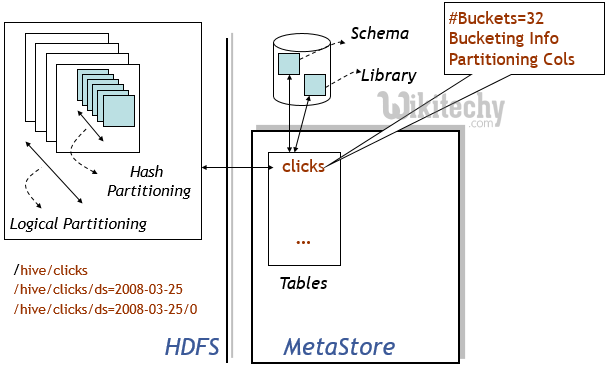
Table Data Models
- Page views table name: pvs
- HDFS directory
------------------/wh/pvs
Partitions Data Models
- Partition columns: ds, ctry
- HDFS subdirectory for ds = 20090801, ctry = US
- HDFS subdirectory for ds = 20090801, ctry = CA
------------------/wh/pvs/ds=20090801/ctry=US
------------------/wh/pvs/ds=20090801/ctry=CA
Buckets Data Models
- Bucket column: user into 32 buckets
- HDFS file for user hash 0
------------------/wh/pvs/ds=20090801/ctry=US/part-00000 - HDFS file for user hash bucket 20
------------------/wh/pvs/ds=20090801/ctry=US/part-00020