pig tutorial - apache pig tutorial - Apache Pig - Architecture - pig latin - apache pig - pig hadoop
- The language used to analyze data in Hadoop using Pig is known as Pig Latin.
- It is a highlevel data processing language which provides a rich set of data types and operators to perform various operations on the data.
- To perform a particular task Programmers using Pig, programmers need to write a Pig script using the Pig Latin language, and execute them using any of the execution mechanisms (Grunt Shell, UDFs, Embedded).
- After execution, these scripts will go through a series of transformations applied by the Pig Framework, to produce the desired output.
- Internally, Apache Pig converts these scripts into a series of MapReduce jobs, and thus, it makes the programmer’s job easy.
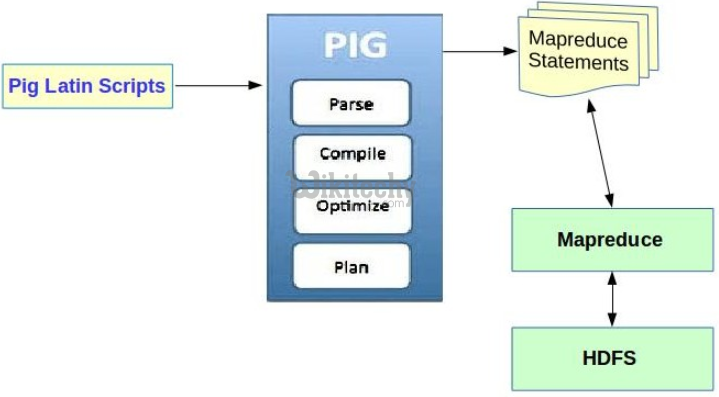
Apache Pig Components
- There are various components in the Apache Pig framework.
Parser
- Initially the Pig Scripts are handled by the Parser.
- It checks the syntax of the script, does type checking, and other miscellaneous checks.
- The output of the parser will be a DAG (directed acyclic graph), which represents the Pig Latin statements and logical operators.
- In the DAG, the logical operators of the script are represented as the nodes and the data flows are represented as edges.
Optimizer
- The logical plan (DAG) is passed to the logical optimizer, which carries out the logical optimizations such as projection and pushdown.

Compiler
- The compiler compiles the optimized logical plan into a series of MapReduce jobs.
Execution engine
- Finally the MapReduce jobs are submitted to Hadoop in a sorted order. Finally, these MapReduce jobs are executed on Hadoop producing the desired results.
Pig Latin Data Model
- The data model of Pig Latin is fully nested and it allows complex non-atomic datatypes such as map and tuple. The diagrammatical representation of Pig Latin’s data model.
Atom
- Any single value in Pig Latin, irrespective of their data, type is known as an Atom.
- It is stored as string and can be used as string and number. int, long, float, double, chararray, and bytearray are the atomic values of Pig.
- A piece of data or a simple atomic value is known as a field.
- Example − ‘raja’ or ‘30’
Tuple
- A record that is formed by an ordered set of fields is known as a tuple, the fields can be of any type. A tuple is similar to a row in a table of RDBMS.
- Example − (Raja, 30)
Bag
- A bag is an unordered set of tuples.
- In other words, a collection of tuples (non-unique) is known as a bag.
- Each tuple can have any number of fields (flexible schema). A bag is represented by ‘{}’.
- It is similar to a table in RDBMS, but unlike a table in RDBMS, it is not necessary that every tuple contain the same number of fields or that the fields in the same position (column) have the same type.
- Example − {(Raja, 30), (Mohammad, 45)}
- A bag can be a field in a relation; in that context, it is known as inner bag.
- Example − {Raja, 30, {9848022338, raja@gmail.com,}}
Map
- A map (or data map) is a set of key-value pairs. The key needs to be of type chararray and should be unique. The value might be of any type. It is represented by ‘[]’
- Example − [name#Raja, age#30]
Relation
- A relation is a bag of tuples. The relations in Pig Latin are unordered (there is no guarantee that tuples are processed in any particular order).