pig tutorial - apache pig tutorial - Apache Pig - Group Operator - pig latin - apache pig - pig hadoop
What is GROUP operator in Apache Pig ?
- The GROUP operator is used to group the data in one or more relations.
- It gathers the data having the same key.
Pig Operations - Grouping
- Produces records with two fields: the key (named group) and the bag of collected records
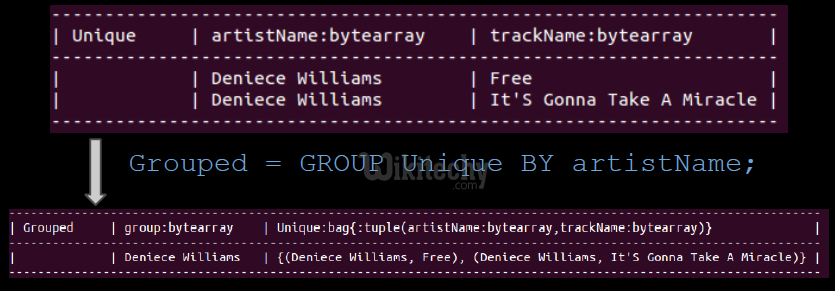
- USING 'collected' - avoids a reduce phase
- GROUP ALL - groups together all of the records into a
single group
GroupedAll = GROUP Users ALL;
CountedAll == FOREACH GroupedAll GENERATE COUNT (Users);
- Creates tuples with the key and a of bag tuples with the same key values
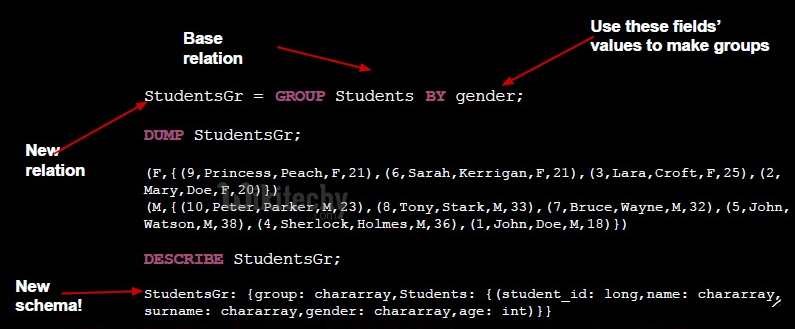
Syntax
grunt> Group_data = GROUP Relation_name BY age;
Example
- Ensure that you have a file named wikitechy_employee_details.txt in the HDFS directory /pig_data/ as shown below.
Wikitechy_employee_details.txt
111,Anu,Shankar,23,9876543210,Chennai
112,Barvathi,Nambiayar,24,9876543211,Chennai
113,Kajal,Nayak,24,9876543212,Trivendram
114,Preethi,Antony,21,9876543213,Pune
115,Raj,Gopal,21,9876543214,Hyderabad
116,Yashika,Kannan,22,9876543215,Delhi
117,siddu,Narayanan,22,9876543216,Kolkata
118,Timple,Mohanthy,23,9876543217,Bhuwaneshwar
- And you have loaded this file into Apache Pig with the relation name wikitechy_employee_details as given below.
grunt> wikitechy_employee_details = LOAD 'hdfs://localhost:9000/pig_data/wikitechy_employee_details.txt' USING PigStorage(',')
as (id:int, firstname:chararray, lastname:chararray, age:int, phone:chararray, city:chararray);
- Let us group the records/tuples in the relation by age as shown below.
grunt> group_data = GROUP wikitechy_employee_details by age;
Verification
- To verify the relation group_data using the DUMP operator as given below.
grunt> Dump group_data;
Output
Next you will get output displaying the contents of the relation named group_data as given below.
Here you can observe that the resulting schema has two columns,
- One is age, by which we have grouped the relation.
- The other is a bag, which contains the group of tuples, employee records with the respective age.
(21,{(114,Preethi,Antony,21,9876543213,Pune),(115, Raj,Gopal,21,9876543214,Hyderabad)}, { } )
(22,{(116,Yashika,Kannan,22,9876543215,Delhi),(117,siddu,Narayanan,22,9876543216,Kolkata)}, { })
(23,{(111,Anu,Shankar,23,9876543210,Chennai),(118,Timple,Mohanthy,23,9876543217,Bhuwaneshwar)}, { })
(24,{(112,Barvathi,Nambiayar,24,9876543211,Chennai),(113,Kajal,Nayak,24,9876543212,Trivendram)}, { })
Now you can see the schema of the table after grouping the data using the describe command as given below.
<b>grunt> Describe group_data; </b>
group_data: {group: int,wikitechy_employee_details: {(id: int,firstname: chararray,
lastname: chararray,age: int,phone: chararray,city: chararray)}}
- If you can get the sample illustration of the schema using the illustrate command as given below.
$ Illustrate group_data;
Output
-------------------------------------------------------------------------------------------------
|group_data| group:int | wikitechy_employee_details:bag{:tuple(id:int,firstname:chararray,lastname:chararray,age:int,phone:chararray,city:chararray)}|
-------------------------------------------------------------------------------------------------
| | 21 | { (114,Preethi,Antony,21,9876543213,Pune),(115, Raj,Gopal,21,9876543214,Hyderabad)}|
| | 22 | {(116,Yashika,Kannan,22,9876543215,Delhi),(117,siddu,Narayanan,22,9876543216,Kolkata)}|
-------------------------------------------------------------------------------------------------
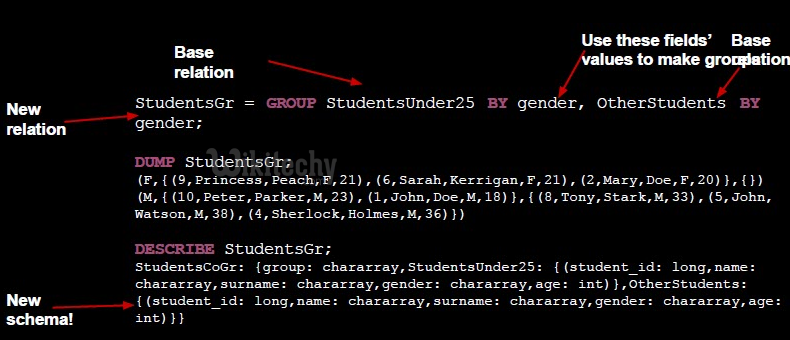
Grouping by Multiple Columns
Group the relation by age and city as given below.
grunt> group_multiple = GROUP wikitechy_employee_details by (age, city);
You can verify the content of the relation named group_multiple using the Dump operator as given below.
<b>grunt> Dump group_multiple; </b>
((21,Pune),{(114,Preethi,Antony,21,9876543213,Pune)})
((21,Hyderabad),{(115, Raj,Gopal,21, 9876543214,Hyderabad)})
((22,Delhi),{(116,Yashika,Kannan,22,9876543215,Delhi)})
((22,Kolkata),{(117,siddu,Narayanan,22,9876543216,Kolkata)})
((23,Chennai),{( 111,Anu,Shankar,23,9876543210,Chennai)})
((23,Bhuwaneshwar),{(118,Timple,Mohanthy,23,9876543217,Bhuwaneshwar)})
((24,Chennai),{( 112,Barvathi,Nambiayar,24,9876543211,Chennai)})
(24,Trivendram),{( 113,Kajal,Nayak,24,9876543212,Trivendram)})
Group All
We can group a relation by all the columns as given below.
grunt> <b>group_all</b> = GROUP <b>wikitechy_employee_details<b> All;
At this time, verify the content of the relation group_all as given below.
<b>grunt> Dump group_all; </b>
(all,{( 118,Timple,Mohanthy,23,9876543217,Bhuwaneshwar),
(117,siddu,Narayanan,22,9876543216,Kolkata),
(116,Yashika,Kannan,22,9876543215,Delhi),
(115,Raj,Gopal,21,9876543214,Hyderabad),
(114,Preethi,Antony,21,9876543213,Pune),
(113,Kajal,Nayak,24,9876543212,Trivendram),
(112,Barvathi,Nambiayar,24,9876543211,Chennai),
(111,Anu,Shankar,23,9876543210,Chennai)}