what is apache pig - apache pig tutorial - What is Apache Pig - pig latin - apache pig - pig hadoop
What is Big Data ?

Hadoop and its Characteristics
Hadoop Ecosystem

Need for Pig

Where to use Pig?
- Quickly changing data processing requirements
- Processing data from multiple channels
- Quick hypothesis testing
- Time sensitive data refreshes
- Data profiling using sampling
What is Pig ?
What does it mean to be Pig?
- Pig can operate on data whether it has metadata or not. It can operate on data that is relational, nested, or unstructured. And it can easily be extended to operate on data beyond files, including key/value stores, databases, etc.
- Pig is intended to be a language for parallel data processing. It is not tied to one particular parallel framework. Check for Pig on Tez
- Pig is designed to be easily controlled and modified by its users.
- Pig allows integration of user code where ever possible, so it currently supports user defined field transformation functions, user defined aggregates, and user defined conditionals.
- Pig supports user provided load and store functions.
- It supports external executables via its stream command and Map Reduce jars via its MapReduce command.
- It allows users to provide a custom partitioner for their jobs in some circumstances and to set the level of reduce parallelism for their jobs.
- Pig processes data quickly. Designers want to consistently improve its performance, and not implement features in ways that weigh pig down so it can't fly.
Apache Pig - Platforms
- PigLatin: Simple but powerful data flow language similar to scripting languages
- PigLatin is a high level and easy to understand data flow programming language
- Provides common data operations (e.g. filters, joins, ordering) and nested types (e.g. tuples, bags, maps)
- It's more natural for analysts than MapReduce
- Opens Hadoop to non-Java programmers
- Pig Engine: Parses, optimizes and automatically executes PigLatin scripts as series of MapReduce jobs on Hadoop cluster
Where does pig live
- Pig and Hadoop versions must be compatible
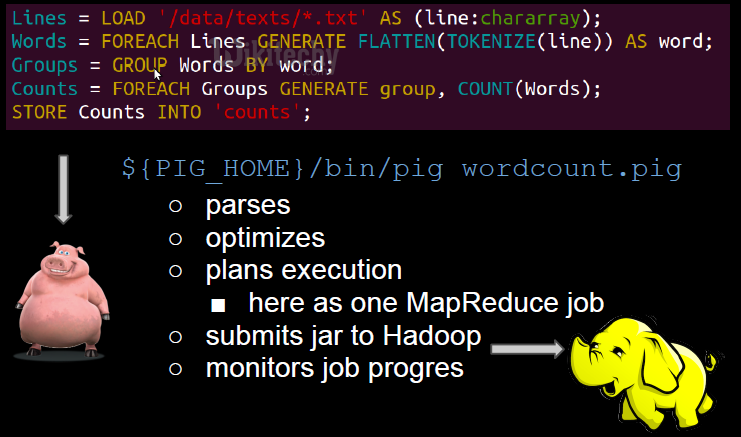
How does Pig work?

Apache pig - data model

- A record that is formed by an ordered set of fields is known as a tuple, the fields can be of any type. A tuple is similar to a row in a table of RDBMS.
- Example: (wikitechy, 30)
- A bag is an unordered set of tuples. In other words, a collection of tuples (non-unique) is known as a bag. Each tuple can have any number of fields (flexible schema).
- A bag is represented by ‘{}’. It is similar to a table in RDBMS, but unlike a table in RDBMS, it is not necessary that every tuple contain the same number of fields or that the fields in th same position (column) have the same type.
- Example: {(Raja, 30), (Mohammad, 45)}
- A bag can be a field in a relation; in that context, it is known as inner bag.
- Example: {wikitechy, 30, {984xxxxx338, wikitechy.com@gmail.com,}}
- A relation is a bag of tuples. The relations in Pig Latin are unordered (there is no guarantee that tuples are processed in any particular order).
- A map (or data map) is a set of key-value pairs. The key needs to be of type chararray and should be unique. The value might be of any type. It is represented by ‘[]’
- Example: [name#wikitechy, age#30]
Internalizing Pig
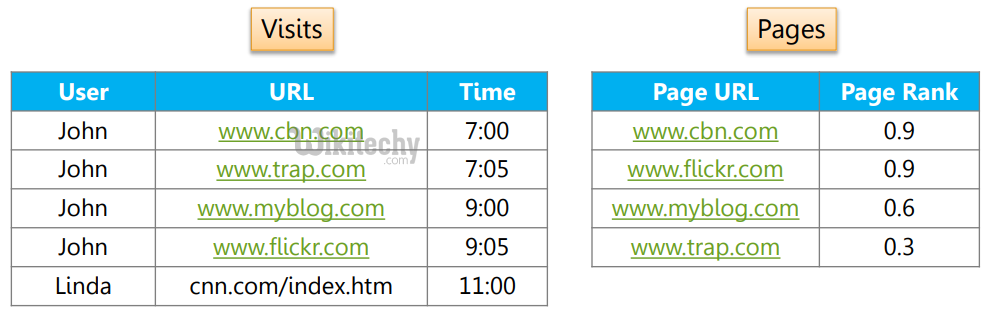
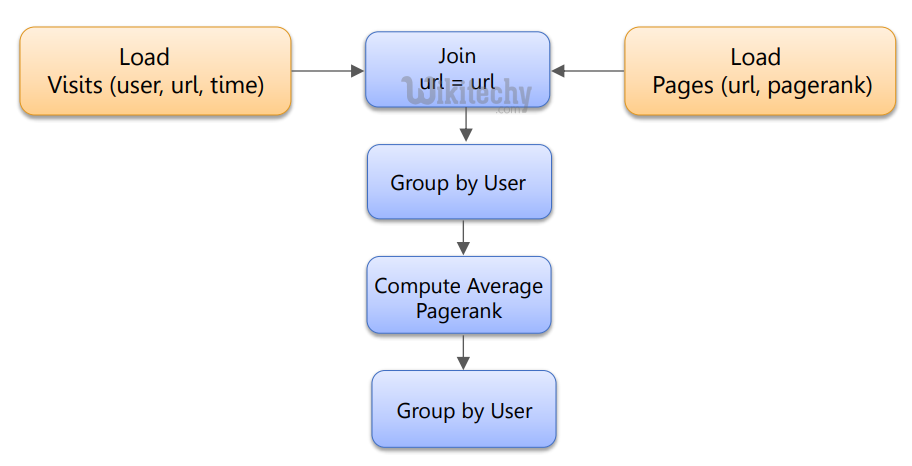
pig in real time
- Data factory operations
- Typically data is brought from multiple servers to HDFS
- Pig is used for cleaning the data and preprocessing it
- It helps data analysts and researchers for quickly prototyping their theories
- Since Pig is extensible, it becomes way easier for data analysts to spawn their scripting language programs (like Ruby, Python programs) effectively against large data sets
Ways to Handle Pig
- It’s interactive mode of Pig
- Very useful for testing syntax checking and ad-hoc data exploration
- Runs set of instructions from a file
- Similar to a SQL script file
- Executes Pig programs from a Java program
- Suitable to create Pig Scripts on the fly
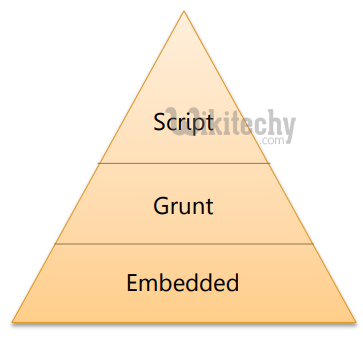
Modes of Pig
- In this mode, entire Pig job runs as a single JVM process
- Picks and stores data from local Linux path
/* local mode */
pig –x local …
java -cp pig.jar org.apache.pig.Main -x local … - In this mode, Pig job runs as a series of map reduce jobs
- Input and output paths are assumed as HDFS paths
/* mapreduce mode */
pig or pig –x mapreduce …
java -cp pig.jar org.apache.pig.Main ...
java -cp pig.jar org.apache.pig.Main -x mapreduce ... Pig Components

Working with Data in pig
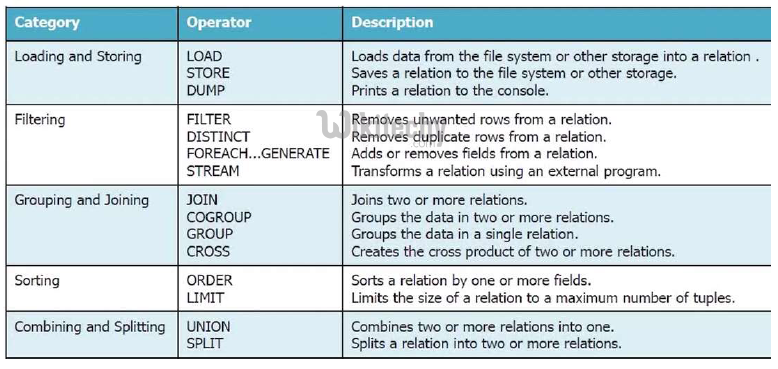
Pig Programs Execution

Apache Pig Sample Script
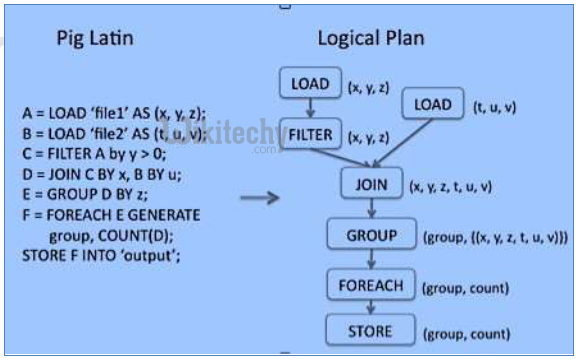
- Loads data from the file system.
- LOAD 'data' [USING function] [AS schema];
- If you specify a directory name, all the files in the directory are loaded.
- A = LOAD ‘t.txt' USING PigStorage('\t') AS (f1:int, f2:int);
- Stores or saves results to the file system.
- STORE alias INTO 'directory' [USING function];
- A = LOAD ‘t.txt' USING PigStorage('\t');
- STORE A INTO USING PigStorage(‘*') AS (f1:int, f2:int);
- Limits the number of output tuples.
- alias = LIMIT alias n;
- A = LOAD ‘t.txt' USING PigStorage('\t') AS (f1:int, f2:int);
- B = LIMIT A 5;
- Selects tuples from a relation based on some condition..
- alias = FILTER alias BY expression;
- A = LOAD ‘t.txt' USING PigStorage('\t') AS (f1:int, f2:int);
- B = FILTER A f2 > 2;
A = LOAD '/user/mapr/training/pig/emp.csv' USING
PigStorage(',') AS (id, firstname, lastname, designation,
city);
DUMP A INTO '/user/mapr/training/pig/output';
STORE A INTO '/user/mapr/training/pig/output'; Apache Pig Example Scripts
X = LOAD '/user/mapr/training/pig/emp_pig1.csv' USING PigStorage(',') AS
(id, firstname, lastname, designation, city);
Y = LOAD '/user/mapr/training/pig/emp_pig2.csv' USING PigStorage(',') AS
(id, firstname, lastname, designation, city);
Z = JOIN X by (designation), Y BY (designation);
final = FILTER Z by X::designation MATCHES 'Manager';
A = GROUP X BY city;
B = FOREACH X GENERATE id, designation;
STORE final INTO '/user/mapr/training/pig/output'; Apache Pig Advanced Scripts
- Get distinct of elements in pig
- process data in parallel in pig
- sample data in pig
- order by elements in pig

- Removes duplicate tuples in a relation.
- alias = DISTINCT alias [PARTITION BY partitioner] [PARALLEL n];
- A = LOAD ‘t.txt' USING PigStorage('\t') AS (f1:int, f2:int);
- B = DISTINCT A;
- Dumps or displays results to screen.
- DUMP alias;
- A = LOAD ‘t.txt' USING PigStorage('\t') AS (f1:int, f2:int);
- DUMP A;
- Sorts a relation based on one or more fields.
- alias = ORDER alias BY { * [ASC|DESC] | field_alias [ASC|DESC] [, field_alias [ASC|DESC] …] } [PARALLEL n];
- A = LOAD ‘t.txt' USING PigStorage('\t') AS (f1:int, f2:int);
- B = ORDER A BY f2;
- DUMP B;
- Computes the union of two or more relations.
- alias = UNION [ONSCHEMA] alias, alias [, alias …];
- L1 = LOAD 'f1' USING (a : int, b : float);
- L2 = LOAD 'f1' USING (a : long, c : chararray);
- U = UNION ONSCHEMA L1, L2;
- DESCRIBE U ;
- U : {a : long, b : float, c : chararray}
- Performs an inner join of two or more relations based on common field values.
- alias = JOIN alias BY {expression|'('expression [, expression …]')'} (, alias BY {expression|'('expression [, expression …]')'} …) [USING 'replicated' | 'skewed' | 'merge' | 'merge-sparse'] [PARTITION BY partitioner] [PARALLEL n];
- A = load 'mydata';
- B = load 'mydata';
- C = join A by $0, B by $0;
- DUMP C;
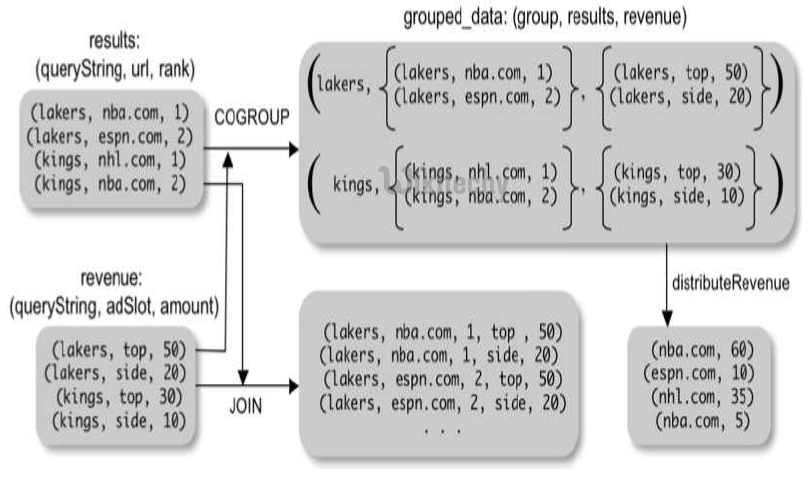
- Performs an outer join of two relations based on common field values.
- alias = JOIN left-alias BY left-alias-column [LEFT|RIGHT|FULL] [OUTER], right-alias BY rightalias- column [USING 'replicated' | 'skewed' | 'merge'] [PARTITION BY partitioner] [PARALLEL n];
- A = LOAD 'a.txt' AS (n:chararray, a:int);
- B = LOAD 'b.txt' AS (n:chararray, m:chararray);
- C = JOIN A by $0 LEFT OUTER, B BY $0;
- DUMP C;
Apache Pig user defined Functions

- Generates data transformations based on columns of data.
- alias = FOREACH { block | nested_block };
- X = FOREACH A GENERATE f1;
- X = FOREACH B { S = FILTER A BY 'xyz‘ == ‘3’; GENERATE COUNT (S.$0); }
- Computes the cross product of two or more relations.
- alias = CROSS alias, alias [, alias …] [PARTITION BY partitioner] [PARALLEL n];
- A = LOAD 'data1' AS (a1:int,a2:int,a3:int);
- B = LOAD 'data2' AS (b1:int,b2:int);
- X = CROSS A, B
- Groups the data in one or more relations.
- The GROUP and COGROUP operators are identical.
- alias = GROUP alias { ALL | BY expression} [, alias ALL | BY expression …] [USING 'collected' | 'merge'] [PARTITION BY partitioner] [PARALLEL n];
- A = load 'student' AS (name:chararray, age:int, gpa:float);
- B = GROUP A BY age;
- DUMP B;
Apache Pig Storage

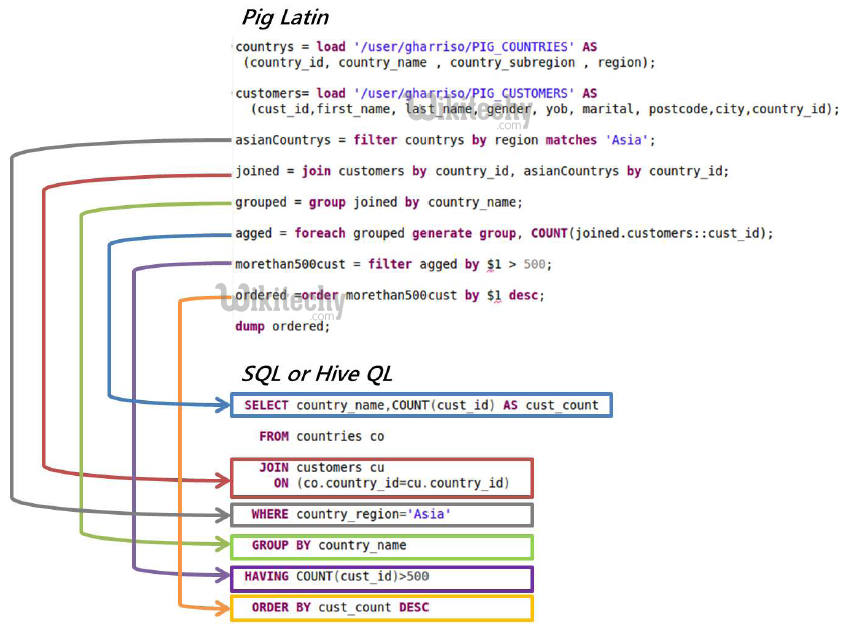
Pig Latin vs hiveql
Pig’s Debugging Operators
Shortcuts for Debugging Operators
Pig Advanced Operations
- Assert a condition on the data..
- ASSERT alias BY expression [, message];
- A = LOAD 'data' AS (a0:int,a1:int,a2:int);
- ASSERT A by a0 > 0, 'a0 should be greater than 0';
- Performs cube/rollup operations.
- alias = CUBE alias BY { CUBE expression | ROLLUP expression }, [ CUBE expression | ROLLUP expression ] [PARALLEL n];
- cubedinp = CUBE salesinp BY CUBE(product,year);
- rolledup = CUBE salesinp BY ROLLUP(region,state,city);
- cubed_and_rolled = CUBE salesinp BY CUBE(product,year), ROLLUP(region, state, city);
- Selects a random sample of data based on the specified sample size.
- SAMPLE alias size;
- A = LOAD 'data' AS (f1:int,f2:int,f3:int);
- X = SAMPLE A 0.01;
- Returns each tuple with the rank within a relation.
- alias = RANK alias [ BY { * [ASC|DESC] | field_alias [ASC|DESC] [, field_alias [ASC|DESC] …] } [DENSE] ];
- B = rank A;
- C = rank A by f1 DESC, f2 ASC;
- C = rank A by f1 DESC, f2 ASC DENSE;
- Executes native MapReduce jobs inside a Pig script.
- alias1 = MAPREDUCE 'mr.jar' STORE alias2 INTO 'inputLocation' USING storeFunc LOAD 'outputLocation' USING loadFunc AS schema [`params, ... `];
- A = LOAD 'WordcountInput.txt';
- B = MAPREDUCE 'wordcount.jar' STORE A INTO 'inputDir' LOAD 'outputDir' AS (word:chararray, count: int) `org.myorg.WordCount inputDir outputDir`;
- Import macros defined in a separate file.
- IMPORT 'file-with-macro';
- Sends data to an external script or program.
- alias = STREAM alias [, alias …] THROUGH {`command` | cmd_alias } [AS schema] ;
- A = LOAD 'data';
- B = STREAM A THROUGH `perl stream.pl -n 5`;
Built-in functions
- Eval functions
- AVG
- CONCAT
- COUNT
- COUNT_STAR
- Math functions
- ABS
- SQRT
- Etc …
- STRING functions
- ENDSWITH
- TRIM
- …
- Datetime functions
- AddDuration
- GetDay
- GetHour
- …
- Dynamic Invokers
- DEFINE UrlDecode InvokeForString('java.net.URLDecoder.decode', 'String String');
- encoded_strings = LOAD 'encoded_strings.txt' as (encoded:chararray);
- decoded_strings = FOREACH encoded_strings GENERATE UrlDecode(encoded, 'UTF-8');
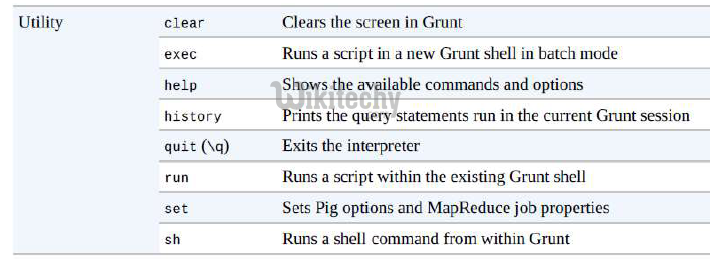
File System Commands with Apache Pig - Hadoop

Hadoop - Apache pig Utility Commands
Some more commands in PIG
- S1 = foreach a generate a1, a1;
- K = foreach A generate $1, $2, $1*$2;
- B = limit a 100;
- Describe A;
- C = UNION A,B;
Using Hive tables with HCatalog
pig -useHCatalog
grunt> records = LOAD ‘School_db.student_tbl'
USING org.apache.hcatalog.pig.HCatLoader();
grunt> DESCRIBE records;
grunt> DUMP records;