pig tutorial - apache pig tutorial - Apache Pig - Reading Data - pig load data - pig latin - apache pig - pig hadoop
What is reading data in pig?
- Apache Pig works on top of Hadoop.
- It is an analytical tool that analyzes large datasets that exist in the Hadoop File System.
- To analyze data using Apache Pig, we have to initially load the data into Apache Pig.
Preparing HDFS:
- In MapReduce mode, Pig reads (loads) data from HDFS and stores the results back in HDFS.
- Therefore start HDFS and create the following sample data in HDFS.
| Student ID | First Name | Last Name | Phone | City |
|---|---|---|---|---|
| 001 | Aadhira | Arushi | 9848022337 | Delhi |
| 002 | Mahi | Champa | 9848022338 | Chennai |
| 003 | Avantika | charu | 9848022339 | Pune |
| 004 | Samaira | Hansa | 9848022330 | Kolkata |
| 005 | Abhinav | Akaash | 9848022336 | Bhuwaneshwar |
| 006 | Amarjeet | Aksat | 9848022335 | Hyderabad |
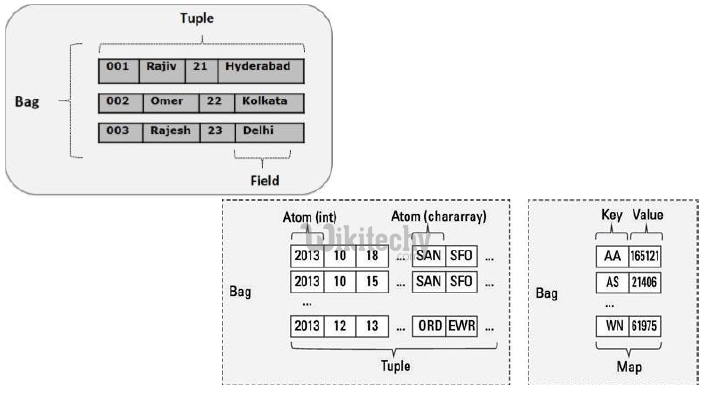
The above dataset contains personal details like id, first name, last name, phone number and city, of six students.
Step 1: Verifying Hadoop
- First of all, verify the installation using Hadoop version command,
$ hadoop version
- If your system contains Hadoop, and if you have set the PATH variable, then you will get the following output −
Hadoop 2.6.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r
e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/Hadoop/hadoop/share/hadoop/common/hadoop
common-2.6.0.jarStep 2: Starting HDFS
- Browse through the sbin directory of Hadoop and start yarn and Hadoop dfs (distributed file system) as shown below.
cd /$Hadoop_Home/sbin/
$ start-dfs.sh
localhost: starting namenode, logging to /home/Hadoop/hadoop/logs/hadoopHadoop-namenode-localhost.localdomain.out
localhost: starting datanode, logging to /home/Hadoop/hadoop/logs/hadoopHadoop-datanode-localhost.localdomain.out
Starting secondary namenodes [0.0.0.0]
starting secondarynamenode, logging to /home/Hadoop/hadoop/logs/hadoop-Hadoopsecondarynamenode-localhost.localdomain.out
$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/Hadoop/hadoop/logs/yarn-Hadoopresourcemanager-localhost.localdomain.out
localhost: starting nodemanager, logging to /home/Hadoop/hadoop/logs/yarnHadoop-nodemanager-localhost.localdomain.outStep 3: Create a Directory in HDFS
- In Hadoop DFS, you can create directories using the command mkdir. Create a new directory in HDFS with the name Pig_Data in the required path as shown below.
$cd /$Hadoop_Home/bin/
$ hdfs dfs -mkdir hdfs//localhost:9000/Pig_DataStep 4: Placing the data in HDFS
- The input file of Pig contains each tuple/record in individual lines.
- And the entities of the record are separated by a delimiter (In our example we used “,”).
- In the local file system, create an input file student_data.txt containing data as shown below.
001, Aadhira,Arushi ,9848022337, Delhi
002, Mahi,Champa,9848022338, Chennai
003, Avantika,charu,9848022339, Pune
004, Samaira,Hansa,9848022330, Kolkata
005, Abhinav,Akaash,9848022336,Bhuwaneshwar
006, Amarjeet,Aksat,9848022335, Hyderabad
- Now, move the file from the local file system to HDFS using put command as shown below. (You can use copyFromLocal command as well.)
$ cd $HADOOP_HOME/bin
$ hdfs dfs -put /home/Hadoop/Pig/Pig_Data/student_data.txt dfs://localhost:9000/pig_data/Verifying the file:
- Use the cat command to verify whether the file has been moved into the HDFS, as shown below.
$ cd $HADOOP_HOME/bin
$ hdfs dfs -cat hdfs://localhost:9000/pig_data/student_data.txt
Output:
- See the content of the file as shown below.
15/10/01 12:16:55 WARN util.NativeCodeLoader: Unable to load native-hadoop
library for your platform... using builtin-java classes where applicable
001, Aadhira,Arushi ,9848022337, Delhi
002, Mahi,Champa,9848022338, Chennai
003, Avantika,charu,9848022339, Pune
004, Samaira,Hansa,9848022330, Kolkata
005, Abhinav,Akaash,9848022336,Bhuwaneshwar
006, Amarjeet,Aksat,9848022335, HyderabadThe Load Operator
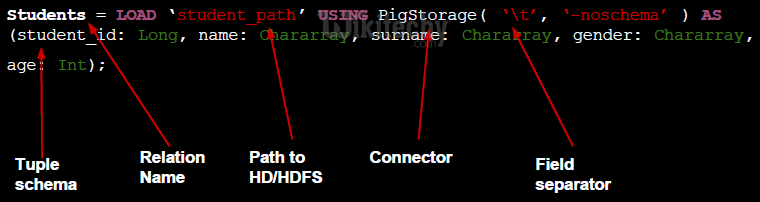
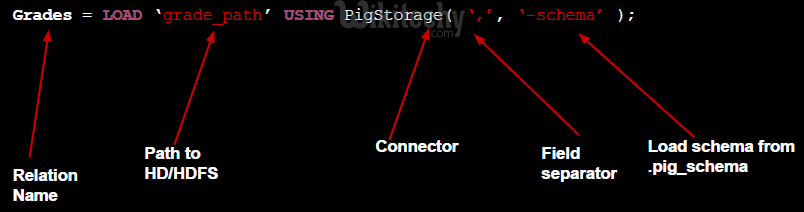
- You can load data into Apache Pig from the file system (HDFS/ Local) using LOAD operator of Pig Latin.
Syntax:
- The load statement consists of two parts divided by the “=” operator.
- On the left-hand side, we need to mention the name of the relation where we want to store the data, and on the right-hand side, we have to define how we store the data.
- Given below is the syntax of the Load operator.
Relation_name = LOAD 'Input file path' USING function as schema;
- Where,
- relation_name − We have to mention the relation in which we want to store the data.
- Input file path − We have to mention the HDFS directory where the file is stored. (In MapReduce mode)
- function − We have to choose a function from the set of load functions provided by Apache Pig (BinStorage, JsonLoader, PigStorage, TextLoader).
- Schema − We have to define the schema of the data. We can define the required schema as follows −
(column1 : data type, column2 : data type, column3 : data type);
Note
- load the data without specifying the schema. In that case, the columns will be addressed as $01, $02, etc… (check).
Example
- As an example, load the data in >student_data.txt in Pig under the schema named Student using the LOAD command.
- Start the Pig Grunt Shell
- First of all, open the Linux terminal. Start the Pig Grunt shell in MapReduce mode as shown below.
$ Pig -x mapreduce
- It will start the Pig Grunt shell as shown below.
15/10/01 12:33:37 INFO pig.ExecTypeProvider: Trying ExecType : LOCAL
15/10/01 12:33:37 INFO pig.ExecTypeProvider: Trying ExecType : MAPREDUCE
15/10/01 12:33:37 INFO pig.ExecTypeProvider: Picked MAPREDUCE as the ExecType
2015-10-01 12:33:38,080 [main] INFO org.apache.pig.Main - Apache Pig version 0.15.0 (r1682971) compiled Jun 01 2015, 11:44:35
2015-10-01 12:33:38,080 [main] INFO org.apache.pig.Main - Logging error messages to: /home/Hadoop/pig_1443683018078.log
2015-10-01 12:33:38,242 [main] INFO org.apache.pig.impl.util.Utils - Default bootup file /home/Hadoop/.pigbootup not found
2015-10-01 12:33:39,630 [main]
INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to hadoop file system at: hdfs://localhost:9000
grunt>Execute the Load Statement
- Now load the data from the file student_data.txt into Pig by executing the following Pig Latin statement in the Grunt shell.
grunt> student = LOAD 'hdfs://localhost:9000/pig_data/student_data.txt'
USING PigStorage(',')
as ( id:int, firstname:chararray, lastname:chararray, phone:chararray,
city:chararray );- Following is the description of the above statement.
| Relation name | We have stored the data in the schema student. | ||||||||||||
| Input file path | We are reading data from the file student_data.txt, which is in the /pig_data/ directory of HDFS. | ||||||||||||
| Storage function | We have used the PigStorage() function. It loads and stores data as structured text files. It takes a delimiter using which each entity of a tuple is separated, as a parameter. By default, it takes ‘\t’ as a parameter. | ||||||||||||
| schema | We have stored the data using the following schema.
|