pig tutorial - apache pig tutorial - Pig latin - pig latin - apache pig - pig hadoop
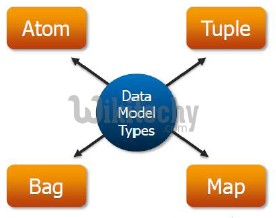
What is pig latin - Pig Programming Model: Data
- Pig operations operate on relations
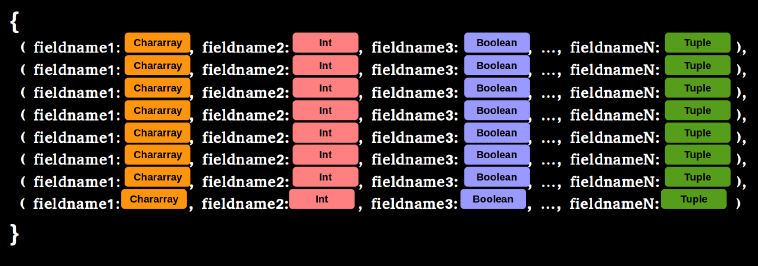
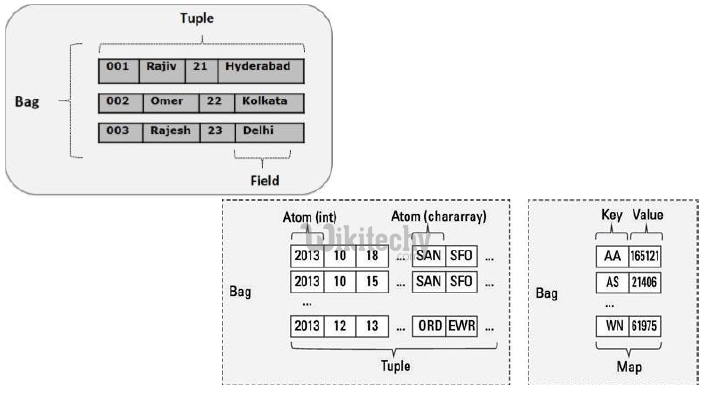
- A relation is a bag
- A bag is a collection of tuples
- A tuple is an ordered set of fields
- A field is any type of data
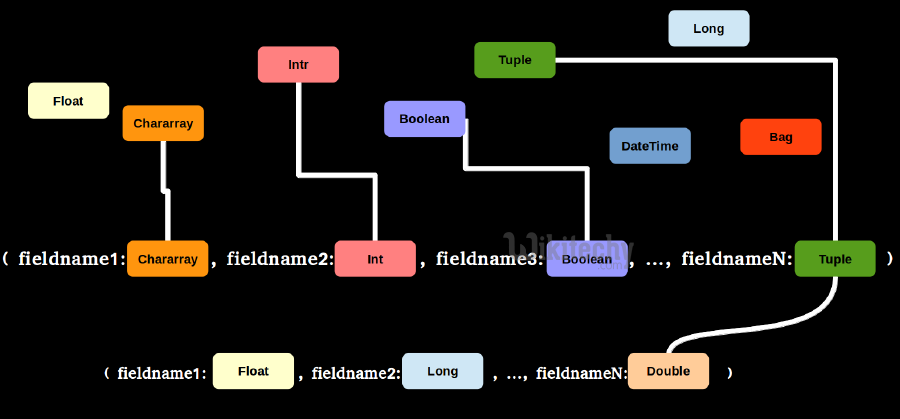
Basic data types:
- Boolean: True, False
- Int and Long: 1, 2, 3, 4, 5
- Float and Double: 2.3, 1.4, 4.5
- Chararray: ‘Hello’, ‘I am a string’
- DateTime: 2014-09-11T12:20:14.1234+00:00
- … more but you won’t probably use them very often
Tuple: A catch-all data type
Bag:
Working with Data
Loading data?
- Data is automatically loaded in a distributed relation
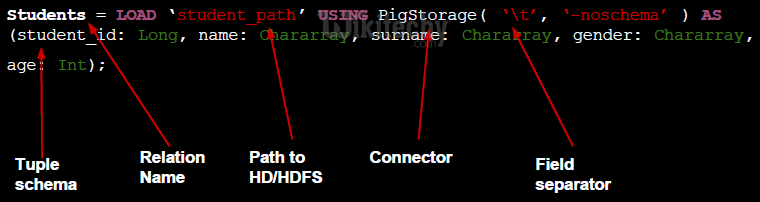
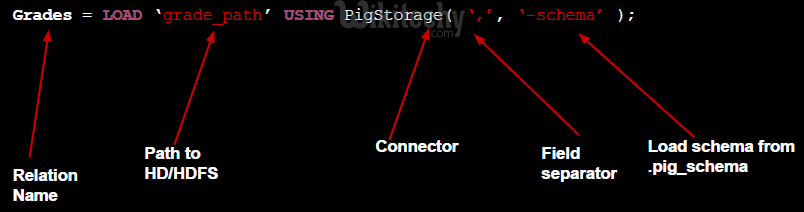
Checking relations’ content
- Prints the content of a relation at standard output
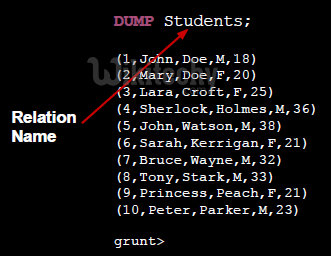
- Prints the schema of the relation at standard output
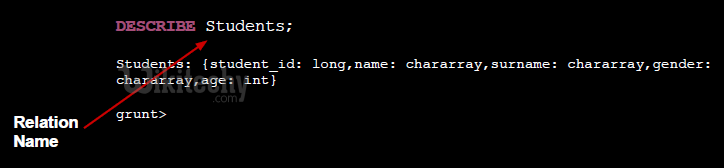
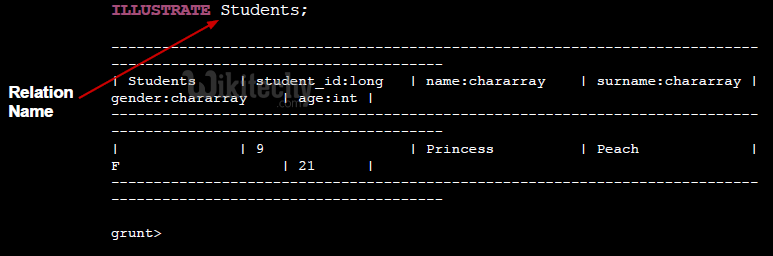
- Prints the schema of the relation and a tuple example at standard output
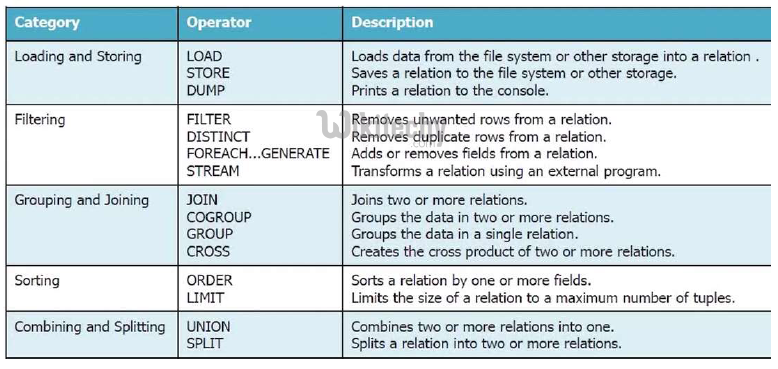
Operating on relations
- Generate new relations by projecting data of a relation


- Let us execute the instruction and… it seems that nothing happens!
- We had some tracing output with LOAD, DUMP, and ILLUSTRATE…
Operating on relations
- LOAD, ILLUSTRATE, DUMP, STORE
Operating on relations
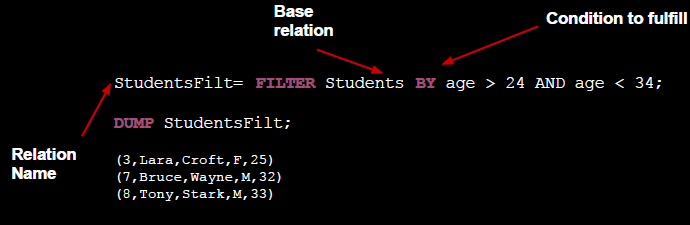
- Generate a new relation by filtering data on a relation
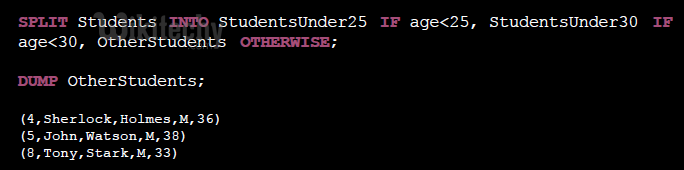
- Splits a relation into multiple relations based on conditions

- Creates tuples with the key and a of bag tuples with the same key values
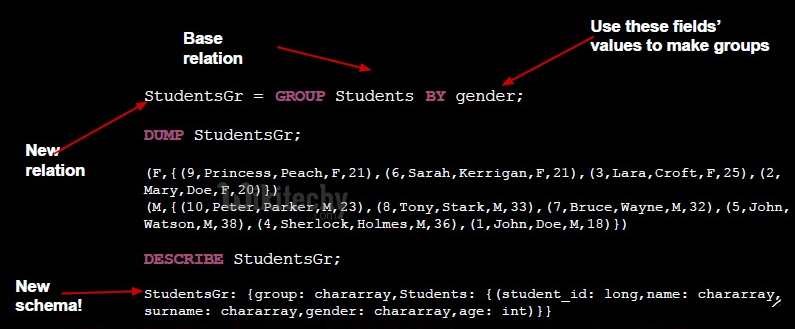
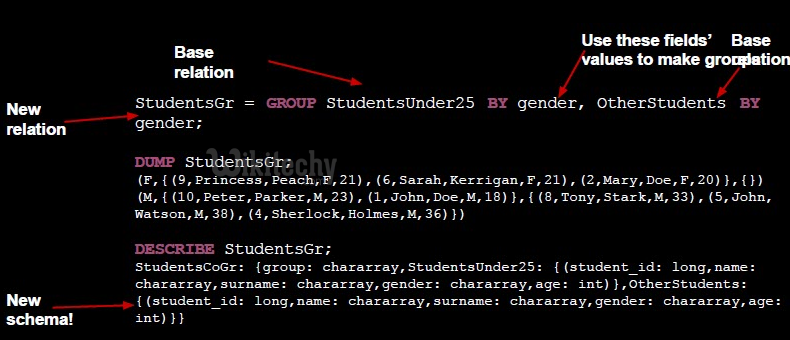
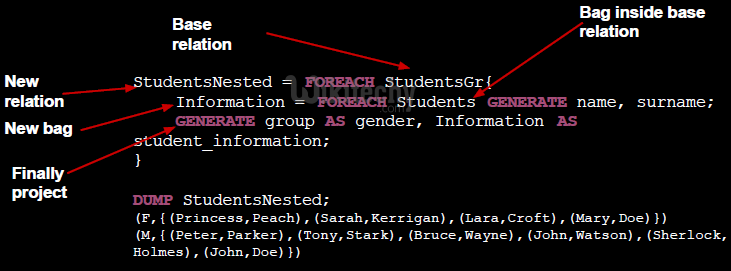
- Operate on data in bags inside a relation and then project
- Our classic database operator for relations!
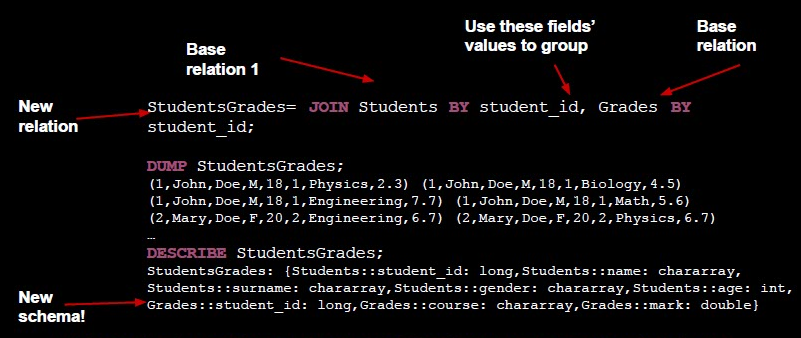
- Our classic database operator for relations!
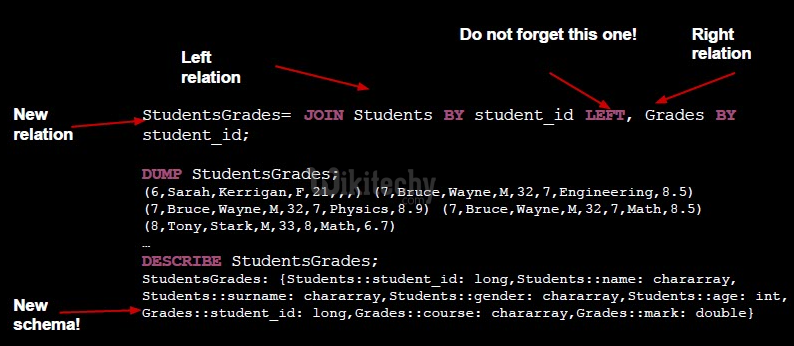
- Cartesian product of two or more relations
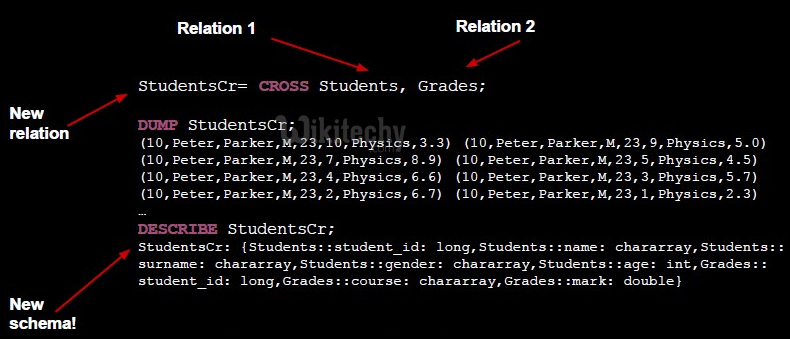
- Joins in the same relation multiple relations

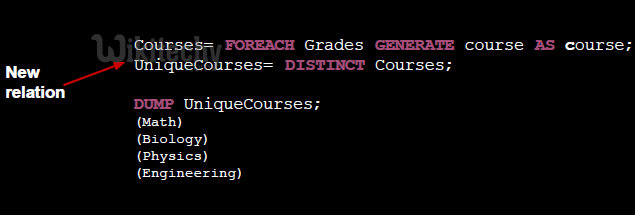
- Only preserves unique tuples
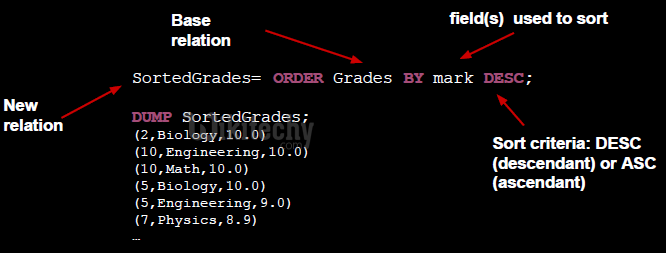
- Sorts relations by a specific criteria
- Truncates relation’s size
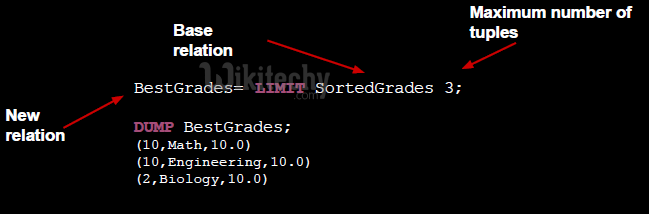
- Appends position of each tuple in the relation
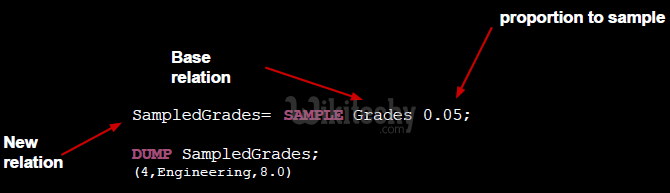
- Sample the relation!
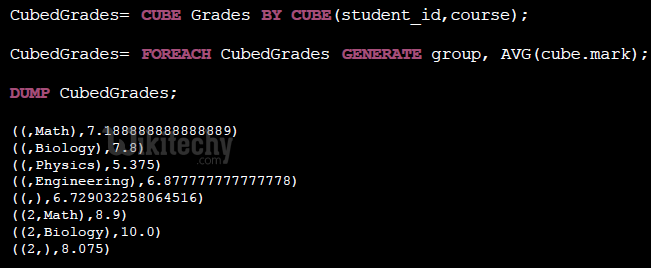
- Is this really useful? Yes! Many aggregates with just one operation
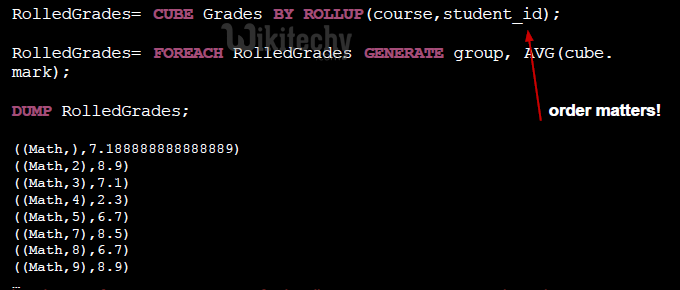
- Like standard CUBE but nulls values are introduced from right to left
- Assert that the whole relation fulfills a condition
- Useful for debugging

- Stores the relation into the local FS or HDFS (usually!)
- Useful for debugging

Where to find useful PigLatin scripts?
- PiggyBank - Pig’s repository of usercontributed
functions
- load/store functions (e.g. from XML)
- datetime, text functions math, stats functions
- DataFu - LinkedIn's collection of Pig UDFs
- statistics functions (quantiles, variance etc.)
- convenient bag functions (intersection, union etc.)
- utility functions (assertions, random numbers, MD5, distance between lat/long pair), PageRank
How to develop PigLatin scripts?
- PigEditor
- syntax/errors highlighting
- check of alias name existence
- auto completion of keywords, UDF names
- PigPen
- graphical visualization of scripts (box and arrows)
- Pig-Eclipse
- Plugins for Vim, Emacs, TextMate
- Usually provide syntax highlighting and code completion
How to run PigLatin scripts?
- adds control flow constructs such as if and for
- avoids the need to invent a new language
- uses a JDBC-like compile, bind, run model