pig tutorial - apache pig tutorial - apache pig with apache tez - pig latin - apache pig - pig hadoop
Apache pig with Apache tez
Tez DAG - Directed Acyclic Graph
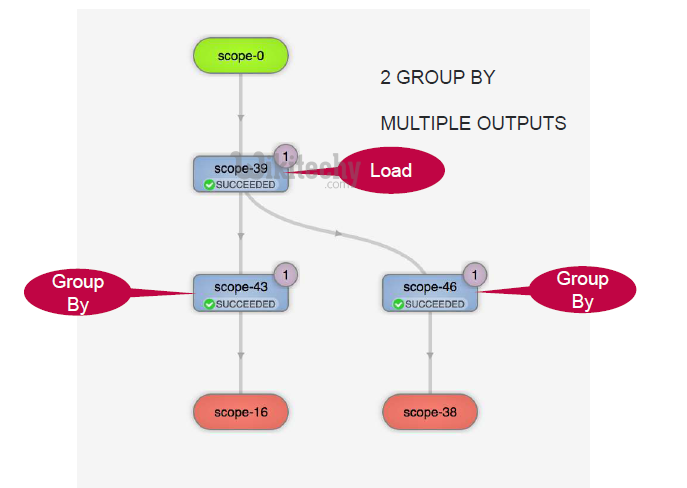
- 2 DISTINCT + JOIN + 2 GROUP BY
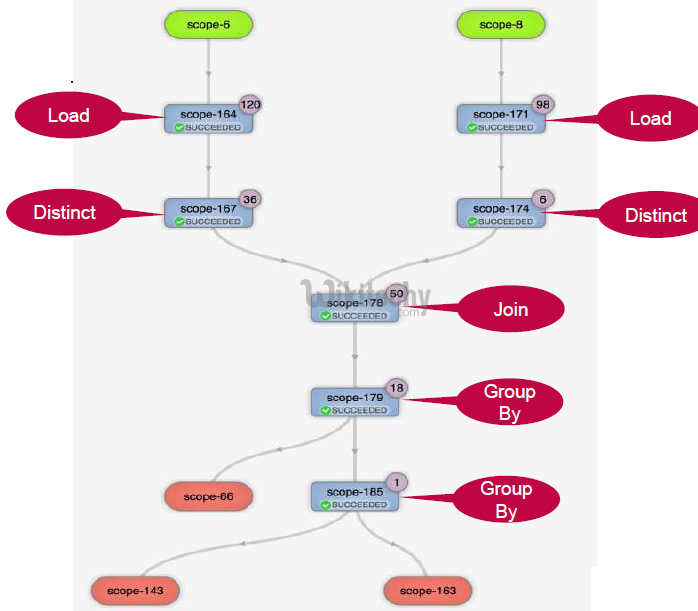
High Depth DAG - Directed Acyclic Graph
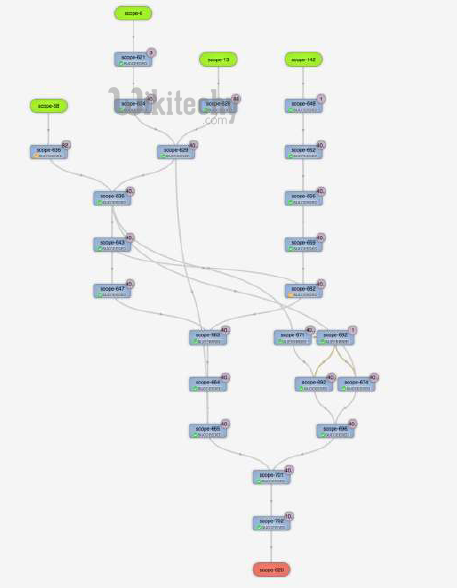
Wide DAG - Directed Acyclic Graph
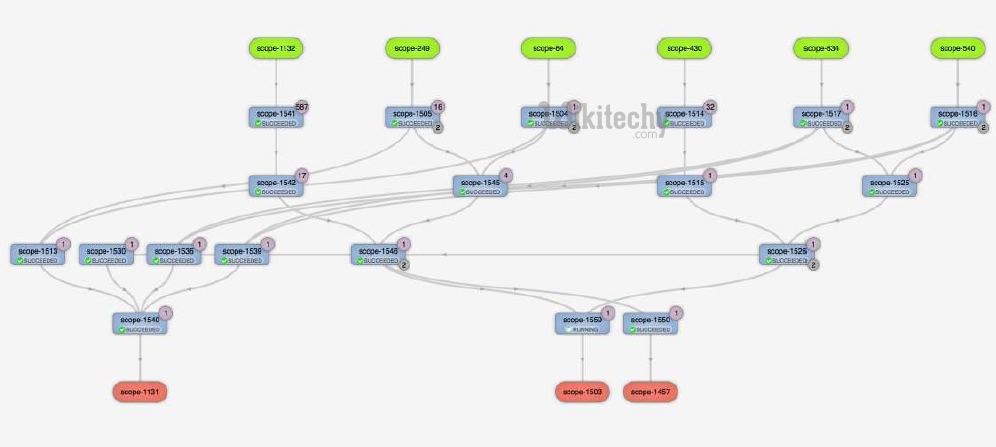
Disjoint Trees DAG - Directed Acyclic Graph

Bloom Filter in TEZ
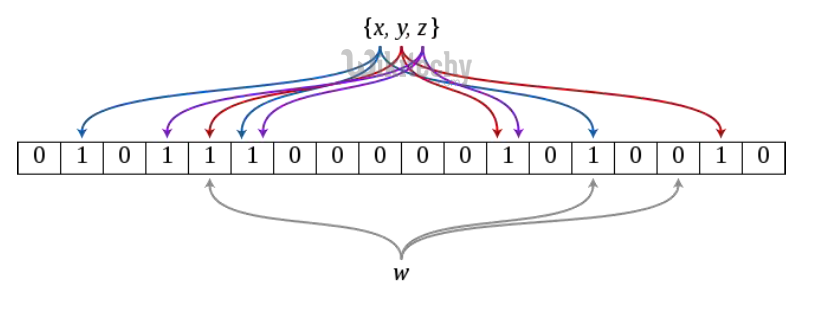
Pig Script - Bloom UDF
define bb BuildBloom('128', '3', 'jenkins');
small = load 'S' as (x, y, z);
grpd = group small all;
fltrd = foreach grpd generate bb(small.x);
store fltrd in ’ mybloom';
exec;
define bloom Bloom('mybloom');
large = load 'L' as (a, b, c);
flarge = filter large by bloom(L.a);
joined = join small by x, flarge by a;
store joined into ’ results';Pig Script - Bloom Join
large = load 'L' as (a, b, c);
small = load 'S' as (x, y, z);
joined = join large by a, small by x using 'bloom';
store joined into 'results';Bloom Filter Tuning
- The size in bytes of the bit vector to be used for the bloom filter.
- A bigger vector size will be needed when the number of distinct keys is higher. Default value is 1048576 (1MB).
- The type of hash function to use.
- Valid values are 'jenkins' and 'murmur'. Default is murmur.
- The number of hash functions to be used in bloom computation.
- It determines the probability of false positives. Higher the number lower the false positives. Too high a value can increase the CPU time.
- Default value is 3.
Apache PIG Hash Join
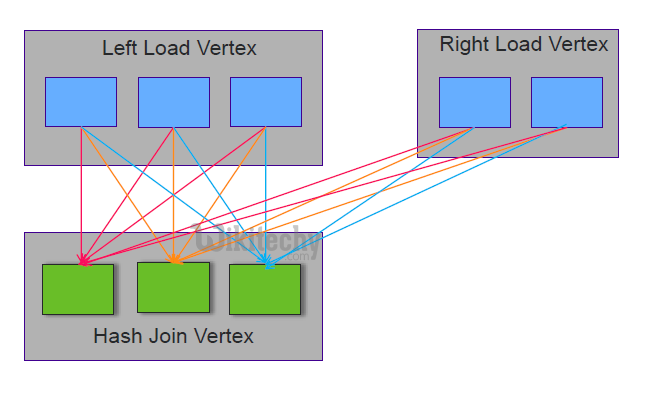
Apache tez - Bloom Join - Map Strategy
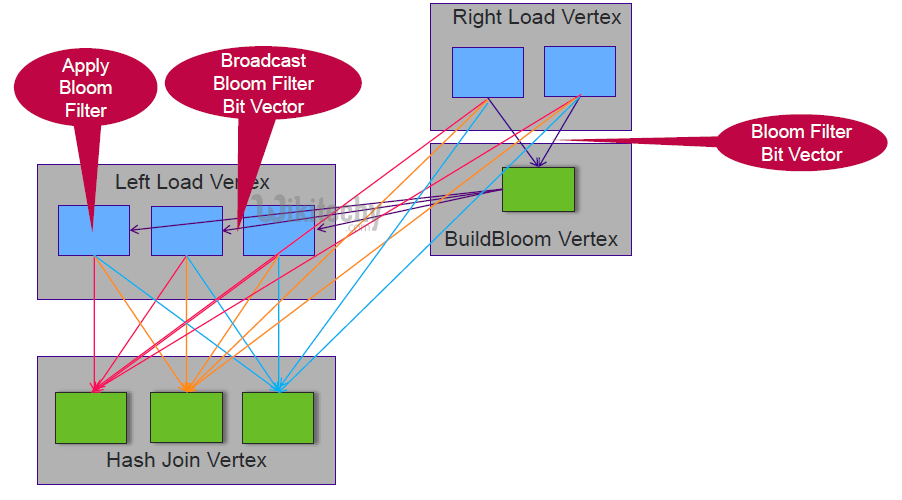
Apache pig - apache tez - Bloom Join - Reduce Strategy
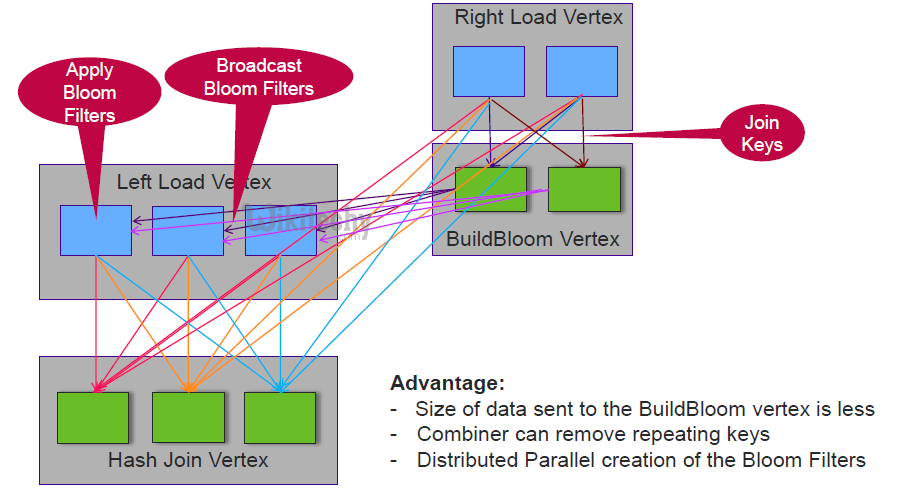
Apache Tez - Partitioned Bloom Filters
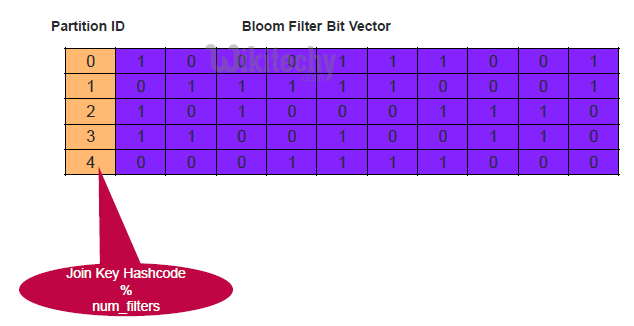
Apache pig - apache tez - Bloom Join - Execution Tuning
- Valid values are 'map' and 'reduce'. Default value is map
- Map strategy creates bloom filters in each map and combines them in the reducer. Fast and ideal for small to medium datasets or distinct join keys.
- Reduce strategy sends the join keys to a reducer and creates the bloom filter there. Ideal for large datasets or repeating join keys.
- The number of bloom filters that will be created
- Will use that many reducers to create the bloom filters in parallel
- Default is 1 for map strategy and 11 for reduce strategy
- Used to turn off the combiner with the reduce strategy when the keys are mostly distinct
- Default is false