pig tutorial - apache pig tutorial - Apache Pig Overview - pig latin - apache pig - pig hadoop
What is Apache Pig ?
- Apache Pig is the scripting platform for processing and analyzing large data sets
- Apache Pig is used with Hadoop where we can perform all the data manipulation operations in Hadoop by using Apache Pig.
- Apache Pig allows Apache Hadoop users to write complex MapReduce transformations which are done using a simple scripting language called Pig Latin.
- Pig Latin language provides various numbers of operators using which the programmers can develop their own functions for reading, writing, and processing data given.
- It is also an abstraction over MapReduce. All the scripts are internally converted to Map and Reduce tasks and Apache Pig has a component which is known as Pig Engine that accepts the Pig Latin scripts as input and converts those scripts into MapReduce jobs which is used for Apache Pig.

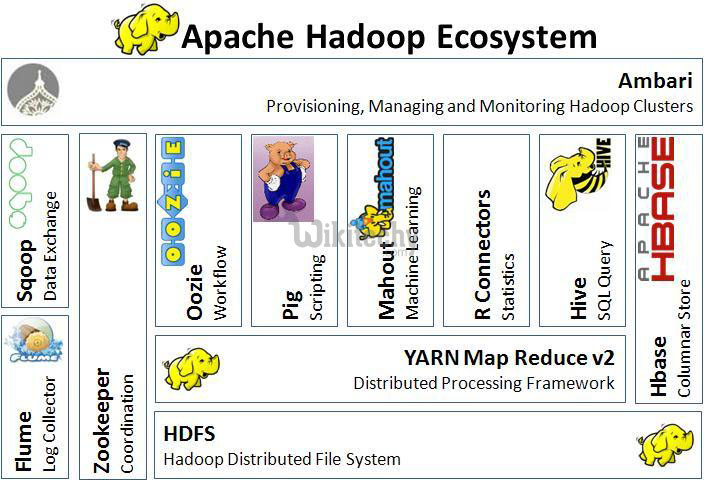
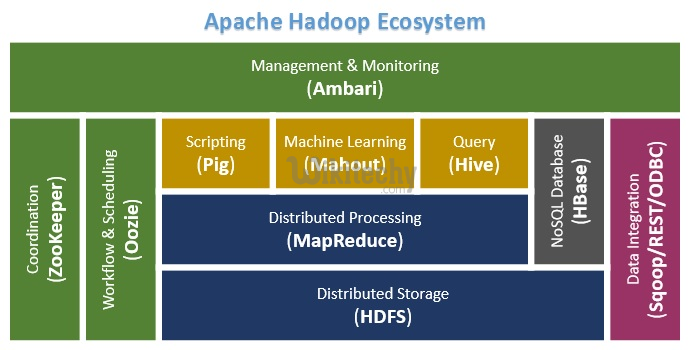
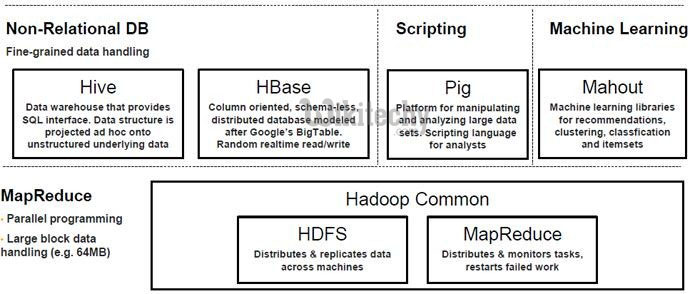
Pig in the Hadoop ecosystem :
learn apache pig - apache pig tutorial - apache pig examples -
hadoop
- apache pig code - apache pig program - apache pig download - apache pig example
Apache Pig - History
- In 2006, Apache Pig was developed originally as a research project in Yahoo for researchers to have an ad-hoc way to create and execute MapReduce jobs on every dataset.
- In 2007, Apache Pig was open source which is done through Apache incubator and it was moved into the Apache Software foundation.
- In 2008, the first version of Apache Pig was released and the first version which was released is version 0.1.1
- In 2010, Apache Pig adoption continued to grow, and Apache Pig graduated from a Hadoop subproject, which is becoming its own top-level Apache pig project.
- In 2017, the latest version for Apache Pig was developed and the version is 0.17.0
Why Do We Need Apache Pig ?
- Some of the Programmers won’t be good at java and hence if they do not know they might have some difficulty while doing hadoop.
- The reason is that if we know java we can understand Hadoop because Java is the platform for hadoop. But if we don’t know java, we cannot understand Hadoop or else we might have some difficulty understanding Hadoop.
- If we can’t understand Java or Hadoop, we can use Apache Pig. Apache Pig is benefit for all programmers
- By using Pig Latin, it is benefit for some programmers to perform MapReduce tasks easily without having to type complex lines of code in Java.
- Apache Pig uses multi-query approach, which reduces the length of codes. For example, if we need to perform some operation for a task that would require us to type 200 lines of code (LoC) in Java. Hence this can be done easily in Apache Pig by typing 10 LoC (Lines of Code) for an operation which is given for a certain task. Apache Pig reduces the development time by 16 times when compared to development time in Java.
- Pig Latin is like SQL-like language and if we are familiar with Apache Pig it is easy to learn SQL Language
- Apache Pig provides us many built-in operators in order to support data operations like joins, filters, ordering and also it supports nested data types like tuples, bags, and maps that were missing from MapReduce.
Features of Pig
- Hence these are some of features of Apache Pig and they are:
- Rich set of operators − It provides rich set of operators to perform operations like join, sort, and filter.
- Ease of programming - Program is ease when Pig Latin is similar to SQL and if we are good at SQL language then it is easier to write Pig Script.
- Optimization opportunities - If the tasks in Apache Pig has an automatically optimize their execution then the programmers will need to focus only on the semantics of the language.
- Extensibility -Extensibility is done when using the existing operators where the users can develop their own functions to read, write, and process data.
- UDF’s (User Defined Functions) - Apache Pig creates User-defined Functions in other programming languages such as Java and invokes them in Pig Scripts.
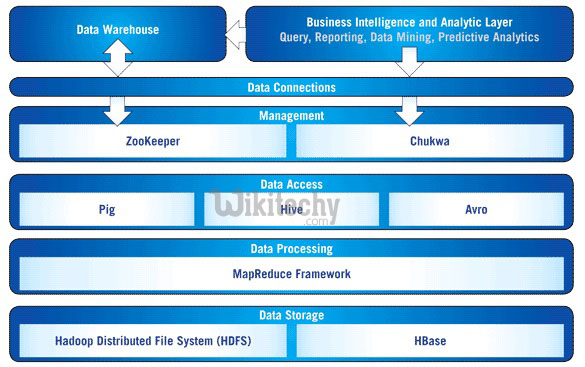
- Handles all kinds of data − Apache Pig analyzes all kinds of data, structured and unstructured data and hence it stores the results of the data in HDFS also known as Hadoop Disturbed File System.
Apache Pig Vs MapReduce
- The table which is given below gives us some of the differences between Apache Pig and MapReduce.
| Apache Pig | MapReduce |
|---|---|
| Apache Pig is a data flow language. | MapReduce is a data processing paradigm. |
| It is a high level language. | MapReduce is low level and rigid. |
| Performing a Join operation in Apache Pig is pretty simple. |
It is quite difficult in MapReduce to perform a Join operation between datasets. |
| Any novice programmer with a basic knowledge of SQL can work conveniently with Apache Pig. |
Exposure to Java is must to work with MapReduce. |
| Apache Pig uses multi-query approach, thereby reducing the length of the codes to a great extent. |
MapReduce will require almost 20 times more the number of lines to perform the same task. |
| There is no need for compilation. On execution, every Apache Pig operator is converted internally into a MapReduce job. |
MapReduce jobs have a long compilation process. |
Apache Pig Vs SQL
- There are some differences between Apache Pig and SQL and it is given below in the format of a table.
| Pig | SQL |
|---|---|
| Pig Latin is a procedural language. | SQL is a declarative language. |
| In Apache Pig, schema is optional. We can store data without designing a schema (values are stored as $01, $02 etc.) |
Schema is mandatory in SQL. |
| The data model in Apache Pig is nested relational. | The data model used in SQL is flat relational. |
| Apache Pig provides limited opportunity for Query optimization. |
There is more opportunity for query optimization in SQL. |
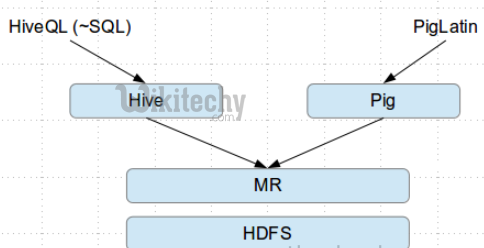
Apache Pig Vs Hive
- In the table which is given below, we have listed some significant points that tell us the difference between Apache Pig and Hive.
| Apache Pig | Hive |
|---|---|
Apache Pig uses a language called Pig Latin. It was originally created at Yahoo. |
Hive uses a language called HiveQL. It was originally created at Facebook. |
| Pig Latin is a data flow language. | HiveQL is a query processing language. |
| Pig Latin is a procedural language and it fits in pipeline paradigm. | HiveQL is a declarative language. |
| Apache Pig can handle structured, unstructured, and semi-structured data. | Hive is mostly for structured data. |
Data-flow vs. declarative programming language
- Step-by-step set of operations
- Each operation is a single transformation
- Set of constraints
- Applied together to an input to generate output
PIG - pig latin vs rdbms
- Schema are predefined and strict
- Tables are flat
- Schema can be defined at run-time for readability
- Pigs eat anything!
- UDF and streaming together with nested data structures make Pig and Pig Latin more flexible
When You Should Use Apache Pig
Applications of Apache Pig
- Apache Pig is used by data scientists in order to perform some tasks which involve ad-hoc processing and quick prototyping. Apache Pig is used to process web log which is used to process huge data sources and time sensitive data loads
- It is also used to perform data processing for some search platforms
- Apache Pig Latin is an application which allows splits in the pipeline
- It also allows developers or programmers to store the data in the pipeline
- It declares some execution plans and provides some operators to perform ETL functions which is also known as Extract, Transform and Load.
Advantages
- It decreases the development time when compared to the development time in Java.
- It is procedural and is easier to follow the commands and provides expressions in the transformation of data
- We can control the execution and If we want to write our own UDF(User Defined Function) it is can be done in execution
- It automatically optimizes the program from the beginning to the end and we can produce an efficient plan to execute.
- It is quite effective for unstructured and structured datasets and it is one of the best tools to make the large unstructured data to structured data.
Disadvantages
- If there is a problem while executing apache pig, it gives us an exec error in udf if the problem is related to syntax or type error.
- Apache Pig support Stackoverflow and Google generally do not lead us to good solutions for the problems given in Apache Pig.
- The debugging of pig scripts is 90 percent of time schema and it may propagate the other steps of the data processing.
- The commands are not executed in Apache Pig unless you dump or store an intermediate final result.