pig tutorial - apache pig tutorial - Pig Example - Apache pig example - pig latin - apache pig - pig hadoop
What is pig?
- Pig is a high level scripting language that is used with Apache Hadoop. Pig excels at describing data analysis problems as data flows. Pig is complete in that you can do all the required data manipulations in Apache Hadoop with Pig.
Problem Statement : 1
- 1,Dhadakebaz,1986,3.2,7560
- 2,Dhumdhadaka,1985,3.8,6300
- 3,Ashi hi banva banvi,1988,4.1,7802
- 4,Zapatlela,1993,3.7,6022
- 5,Ayatya Gharat Gharoba,1991,3.4,5420
- 6,Navra Maza Navsacha,2004,3.9,4904
- 7,De danadan,1987,3.4,5623
- 8,Gammat Jammat,1987,3.4,7563
- 9,Eka peksha ek,1990,3.2,6244
- 10,Pachhadlela,2004,3.1,6956
- $ pig -x local
- grunt> movies = LOAD 'movies_data.csv' USING PigStorage(',') as (id,name,year,rating,duration)
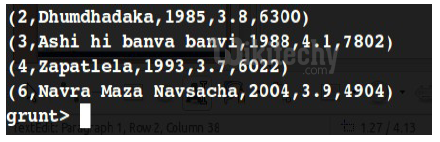
- grunt> dump movies; it displays the contents
- grunt> movies_greater_than_35 = FILTER movies BY (float)rating > 3.5;
- grunt> dump movies_greater_than_35;
Store the results data from pig
- grunt> store movies_greater_than_35 into 'my_movies';
- It stores the result in local file system directory named 'my_movies'.
Display the result
Load command
- The load command specified only the column names. We can modify the statement as follows to include the data type of the columns:
grunt> movies = LOAD
'movies_data.csv' USING
PigStorage(',') as (id:int,
name:chararray, year:int,
rating:double, duration:int);
Check the filters
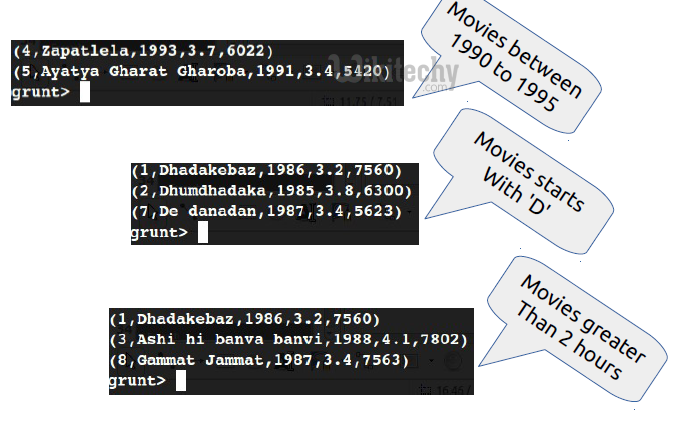
grunt> movies_between_90_95 = FILTER
movies by year > 1990 and year < 1995; grunt> movies_starting_with_D = FILTER
movies by name matches 'D.*';grunt> movies_duration_2_hrs = FILTER
movies by duration > 7200; Pig Code Output
Foreach statement in Pig
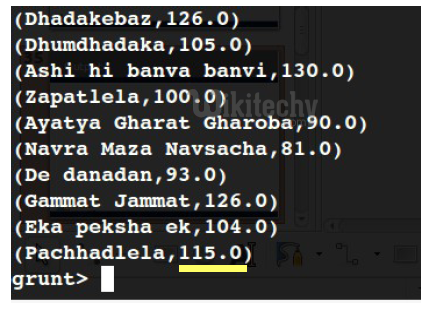
grunt> movie_duration = FOREACH movies
GENERATE name, (double)(duration/60);Output of the foreach statement in PIG
Group Statement in PIG
grunt> grouped_by_year = group movies
by year;
grunt> count_by_year = FOREACH
grouped_by_year GENERATE group,
COUNT(movies); 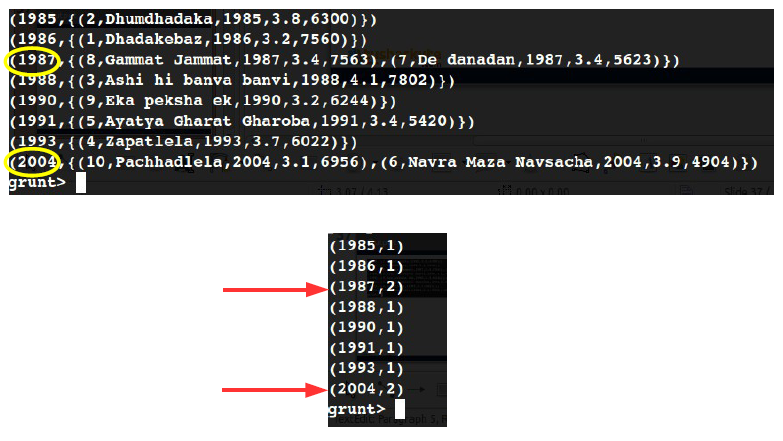
Order by in PIG Statement
grunt> desc_movies_by_year = ORDER
movies BY year ASC;
grunt> DUMP desc_movies_by_year;grunt> asc_movies_by_year = ORDER movies
by year DESC;
grunt> DUMP asc_movies_by_year; 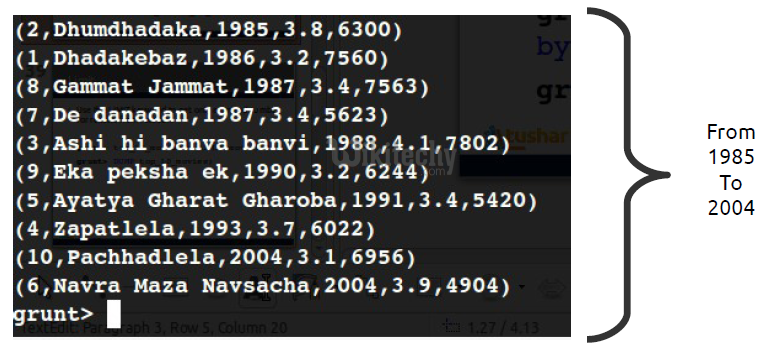
- Use the LIMIT keyword to get only a limited number for results from relation.
grunt> top_5_movies = LIMIT movies 5;
grunt> DUMP top_10_movies; 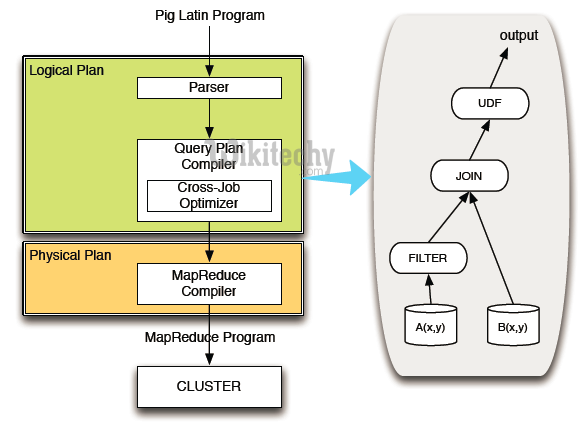
Pig: Modes of Execution
- Script Mode
- Grunt Mode
- Embedded Mode
Script mode in pig
$ vim scriptfile.pig
A = LOAD 'script_file';
DUMP A;
$ pig x
local scriptfile.pig Grunt mode in pig
$ pig -x local
grunt> A = LOAD 'grunt_file';
grunt> DUMP A;grunt> run scriptfile.pig
grunt> exec scriptfile.pigEmbedded mode in PIG
Problem Statement 2:
- Using Pig find the most occurred start letter.
Solution:
Case 1:
- Load the data into bag named "lines". The entire line is stuck to element line of type character array.
grunt> lines = LOAD "/user/Desktop/data.txt" AS (line: chararray);
Case 2:
- The text in the bag lines needs to be tokenized this produces one word per row.
grunt>tokens = FOREACH lines GENERATE flatten(TOKENIZE(line)) As token: chararray; Case 3:
- To retain the first letter of each word type the below command .This commands uses substring method to take the first character.
grunt>letters = FOREACH tokens GENERATE SUBSTRING(0,1) as letter : chararray;
Case 4:
- Create a bag for unique character where the grouped bag will contain the same character for each occurrence of that character.
grunt>lettergrp = GROUP letters by letter;
Case 5:
- The number of occurrence is counted in each group.
grunt>countletter = FOREACH lettergrp GENERATE group , COUNT(letters); Case 6:
- Arrange the output according to count in descending order using the commands below.
grunt>OrderCnt = ORDER countletter BY $1 DESC;
Case 7:
- Limit to One to give the result.
grunt> result =LIMIT OrderCnt 1;
Case 8:
- Store the result in HDFS . The result is saved in output directory under sonoo folder.
grunt> STORE result into 'home/sonoo/output';